Repository
Introduction
The Repository tool is where data files associated with each case in the current cohort can be browsed and downloaded. It also offers file filters for identifying files of interest.
NOTE: Filters within the Repository are applied to the files associated with your cohort. If your goal is to filter the cases within your cohort, use the filters located in the Cohort Builder.
The Repository tool can be reached in one of these two ways:
- Choosing the Repository link in the GDC Data Portal header
- Clicking the play button on the Repository card in the Analysis Center

Choosing a Cohort
The files displayed in the Repository will reflect the files that are associated with the active cohort. The current active cohort is displayed in the Main Toolbar.

For users who want to browse all files that are available at the GDC, create a new cohort via the main toolbar and use it with the Repository tool.
Filtering a Set of Files
As most users are searching for specific types of files, a set of commonly-used default facet cards can be used in the left panel of the Repository tool to allow users to filter the files presented in the table on the right. The facet cards are as follows:
- Experimental Strategy: Experimental strategies used for molecular characterization of the cancer
- WGS Coverage: Range of coverage for WGS aligned reads
- Data Category: A high-level data file category, such as "Raw Sequencing Data" or "Transcriptome Profiling"
- Data Type: Data file type, such as "Aligned Reads" or "Gene Expression Quantification". Data Type is more granular than Data Category.
- Data Format: Format of the data file
- Workflow Type: Bioinformatics workflow used to generate or harmonize the data file
- Platform: Technological platform on which experimental data was produced
- Access: Indicator of whether access to the data file is open or controlled
- Tissue Type: Type of tissue collected, such as "Normal" or "Tumor"
- Tumor Descriptor: Description of the disease present in the tumor specimen, such as "Primary" or "Metastatic"
- Specimen Type: Type of material taken. This includes particular types of cellular molecules, cells, tissues, organs, body fluids, embryos, and body excretory substances.
- Preservation Method: Method used to preserve the sample, such as "OCT" or "Snap Frozen"
Values within each facet can be sorted alphabetically by choosing the "Name" header on the top left of each card. Alternatively, the "Files" header may be selected to sort the values by the number of files available.
Note that the categories displayed in the filters represent the values available for the active cohort.
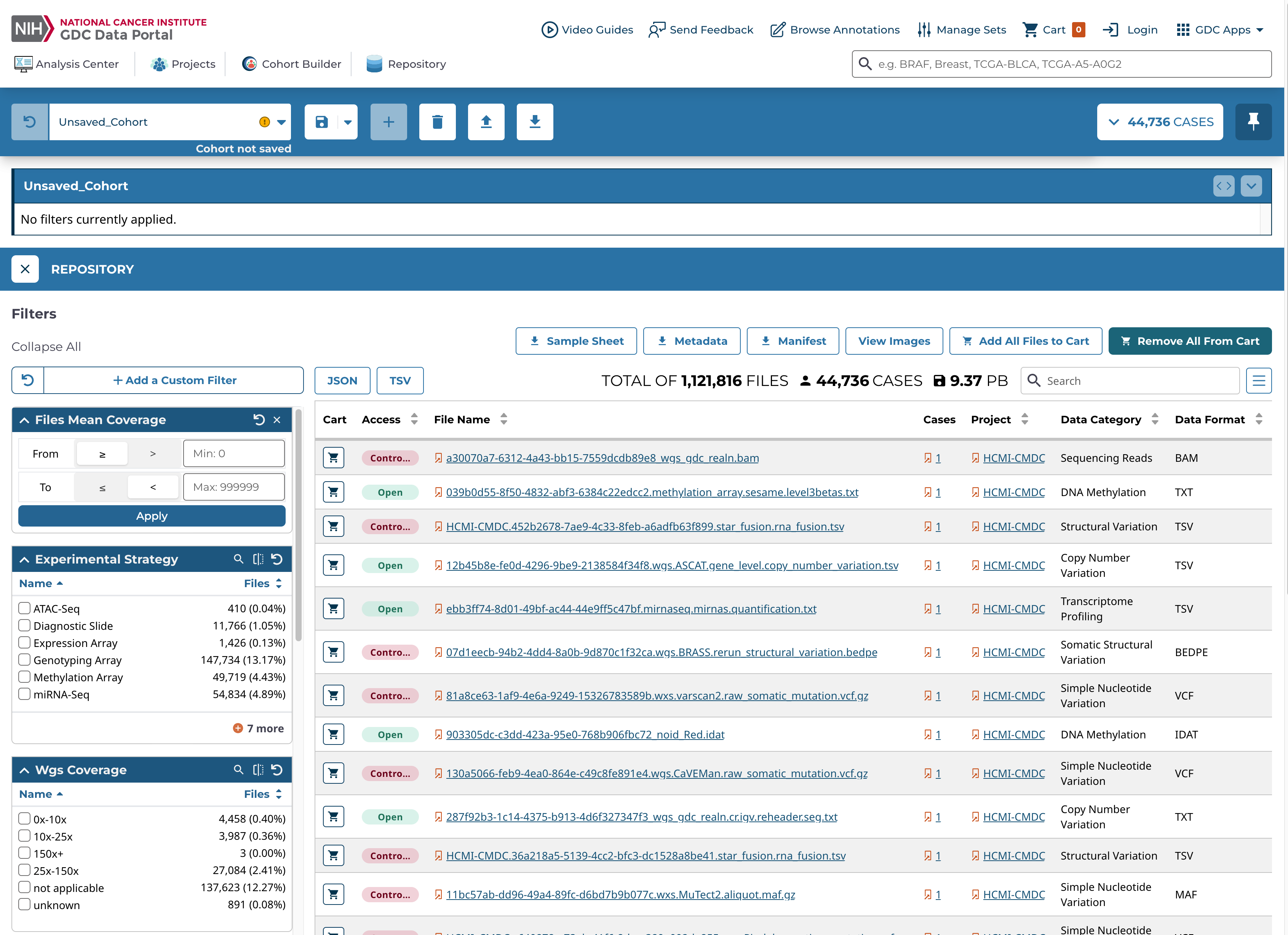
If a different filter needs to be used, a custom filter can be applied by choosing the "Add a Custom Filter" button at the top of the default filters. Each custom filter can then be searched and chosen within the pop-up window. Once a custom filter is selected, a new filter card will appear at the top of the default filters. Custom filters can be removed from the Repository by choosing the X at the top right of each filter card.

Viewing Images
To view images associated with the active cohort, select the View Images button above the files table to launch the Slide Image Viewer.
Files Table
The table shows the list of all the files associated with the active cohort, subject to any filtering that has been applied in the Repository. By default, the table provides the following information for each file:
- Access: Displays whether the file is open or controlled access. Users must login to the GDC Portal and have the appropriate credentials to access these files.
- File Name: Name of the file. Clicking the link will bring the user to the File Summary Page.
- Cases: The number of cases associated with the file
- Project: The Project that the file belongs to. Clicking the link will bring the user to the Project Summary Page.
- Data Category: Type of data
- Data Format: The file format
- File Size: The size of the file
- Annotations: Whether there are any annotations
Additional information such as Data Type and Experimental Strategy can be displayed using the Customize Columms button above the table. The table can be sorted by clicking on the headers, and the search bar above the table can be used to locate specific files.
The JSON / TSV buttons will download the files' details (file name, file size, data category, access type, etc.) in JSON and TSV format, respectively.
Downloading a Set of Files
When filtering has been completed, files are ready to be downloaded. Depending on the number and size of files, the GDC has several options and recommendations for downloading them. While any amount of data can be downloaded using the GDC Data Transfer Tool or the API, files can be downloaded directly from the Data Portal if the size is 5 GB or less in total and the number of files does not exceed 10,000. For any downloads larger than 5 GB or 10,000 files, it's recommended that the download be performed using the GDC Data Transfer Tool.
Generating a Manifest File for the Data Transfer Tool
Select the Manifest button above the table to generate a manifest file required for batch download using the Data Transfer Tool. The manifest contains a list of the UUIDs corresponding to the files associated with the active cohort, subject to any filtering in the Repository.
Adding/Removing Files to the Cart for Download
Downloads can also be performed using the Cart by first adding a set of files to the Cart. This can be done using the following methods:
- Clicking the cart icon on the left of each file. This will toggle between adding to and removing the file from the cart.
- Selecting the Add All Files to Cart button. This will add all the files in the current cohort to the Cart, subject to any filtering that has been applied in the Repository.
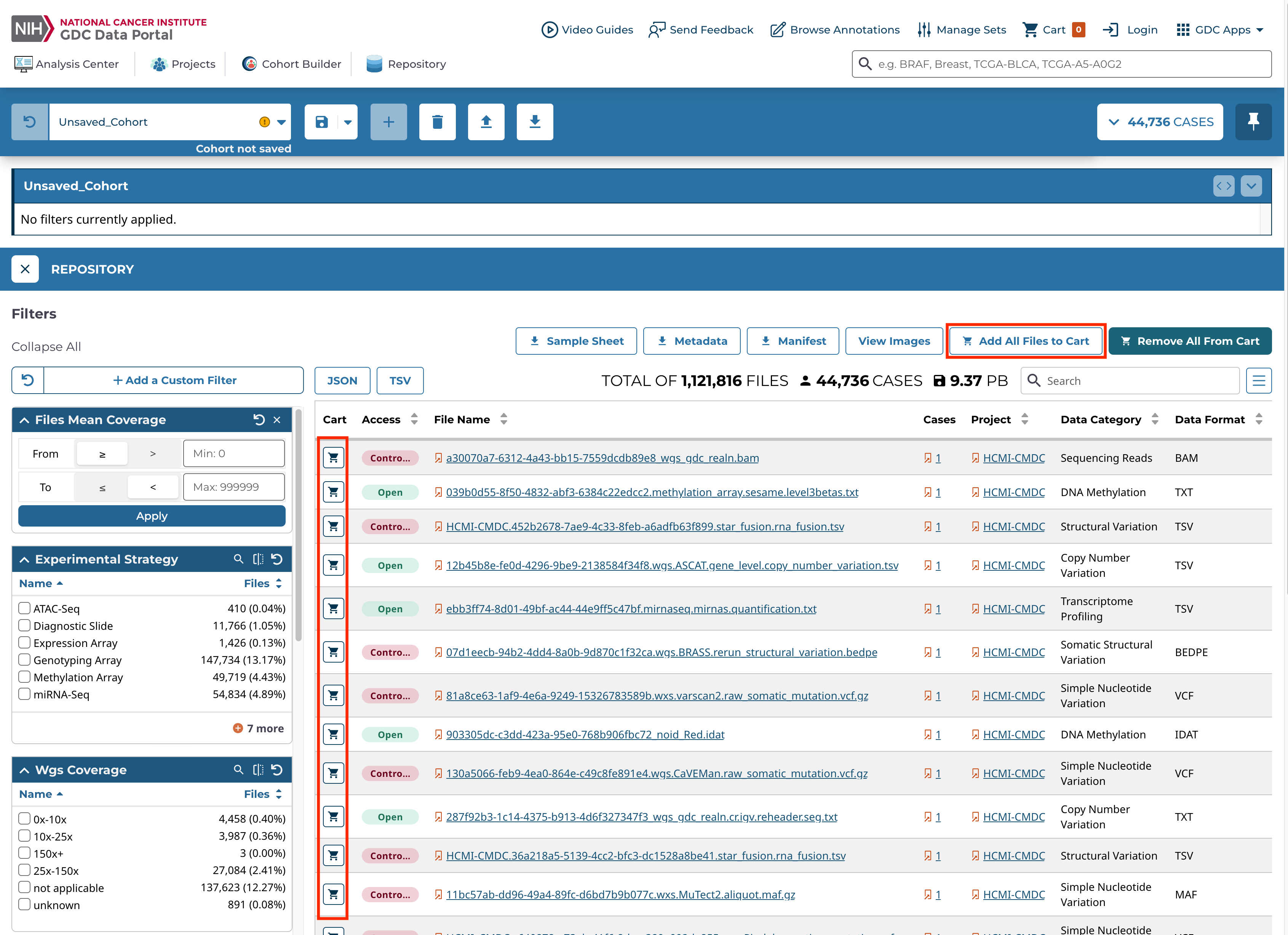
Cart
The Cart page can then be reached by clicking the Cart icon at the top right of the portal.
At the upper-right of the page is a summary of all files currently in the cart:
- Number of files
- Number of cases associated with the files
- Total file size
The Cart page displays the file count by project and authorization level, as well as a table of all files that have been added to the Cart. Files can be removed from the Cart using the trash icons at the left of each file in the table or by selecting the "Remove from Cart" option at the top of the Cart page, which removes either all files or the unauthorized ones.
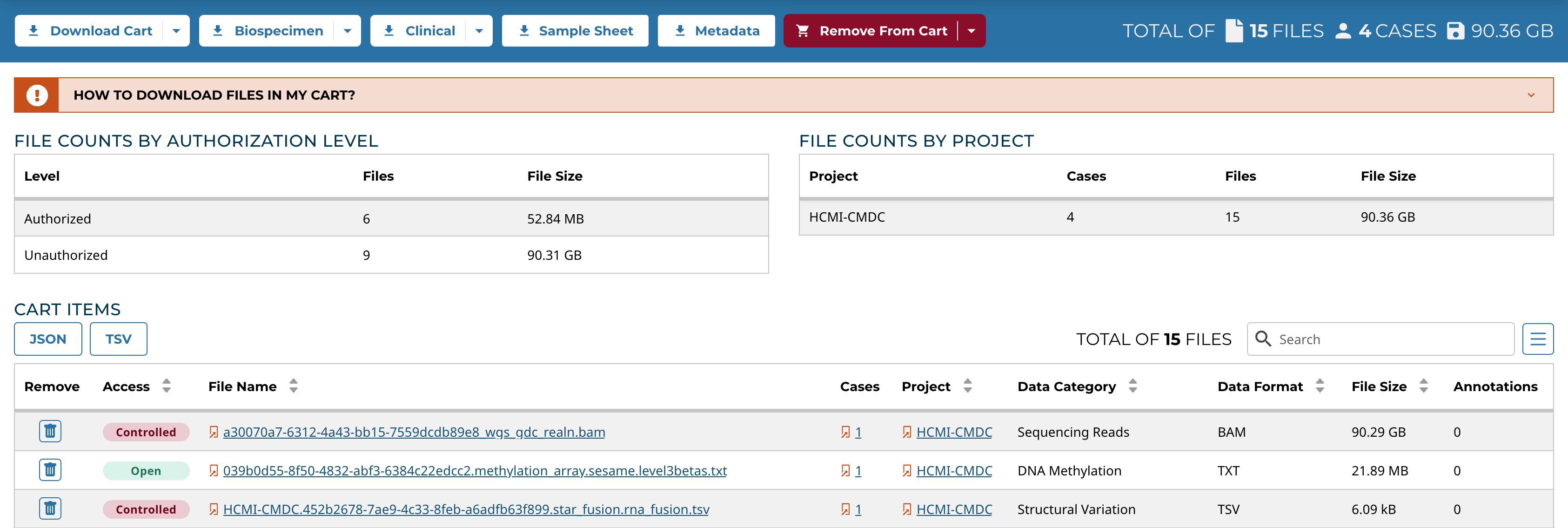
Cart Items Table
The Cart Items table shows the list of all the files that were added to the Cart and has the same functionality as the table in the Repository. By default, it displays the following information for each file:
- Access: Displays whether the file is open or controlled access. Users must login to the GDC Portal and have the appropriate credentials to access these files.
- File Name: Name of the file. Clicking the link will bring the user to the File Summary Page.
- Cases: The number of cases associated with the file
- Project: The Project that the file belongs to. Clicking the link will bring the user to the Project Summary Page.
- Data Category: Type of data
- Data Format: The file format
- File Size: The size of the file
- Annotations: Whether there are any annotations
Additional information can be displayed using the Customize Columms button above the table. Sort can be applied by clicking on the table headers, and the search bar provides additional options for locating specific files. Details of the files can be downloaded using the JSON and TSV buttons above the table.
Downloading Files from the Cart
To download files in the Cart, select the Download Cart button and choose either:
- Manifest: Downloads a manifest for the files that can be passed to the GDC Data Transfer Tool. A manifest file contains a list of the UUIDs that correspond to the files in the cart.
- Cart: Download the files directly through the browser. Users have to be cautious of the amount of data in the cart since this option will not optimize bandwidth and will not provide resume capabilities. This option can only be used if the total size of the files in the Cart does not exceed 5 GB.
Additional Data Download
Additional data can be downloaded from the Cart page by using the buttons available at the top of the page.

- Biospecimen: TSV / Biospecimen: JSON - This includes all biospecimen information from the cases that are associated with the files (available as TSV or JSON).
- Clinical: TSV / Clinical: JSON - This includes all clinical information from the cases that are associated with the files (available as TSV or JSON)
- Sample Sheet: A TSV with commonly-used elements associated with each file, such as tissue type and tumor descriptor.
- Sample ID: A unique identifier assigned to a sample, often containing information about the sample's origin and type
- Tissue Type: Indicates whether or not the tissue sample was normal or tumorous.
- Tumor Descriptor: A descriptor indicating the clinical status of the tumor sample (e.g., primary, metastatic) or specifying when this field is not applicable, such as for normal samples.
- Specimen Type: Describes the kind of biological material that was collected and processed for the sample.
- Preservation Method: The method used to preserve the sample after collection.
- Metadata: This includes all of the metadata associated with each and every file in the cart. Note that this file is only available in JSON format and may take several minutes to download.
In situations where only one sample is associated with a file, each column will have one value present. However, when multiple samples are associated with one file, columns may contain multiple comma-separate values, with the first value corresponding to the first sample, second value to second sample, and so forth.
The following sample sheet is an example of multiple values present within each column.
| Case ID | Sample ID | Tissue Type | Tumor Descriptor | Specimen Type | Preservation Method |
|---|---|---|---|---|---|
| HCM-BROD-0009-C25, HCM-BROD-0009-C25 | HCM-BROD-0009-C25-10A, HCM-BROD-0009-C25-85A | Normal, Tumor | Not Applicable, Metastatic | Peripheral Blood NOS, 3D Organoid | Unknown, Frozen |
| HCM-BROD-0009-C25, HCM-BROD-0009-C25 | HCM-BROD-0009-C25-06A, HCM-BROD-0009-C25-10A | Tumor, Normal | Metastatic, Not Applicable | Unknown, Peripheral Blood NOS | Frozen, Unknown |
The example should be interpreted as the following:
| Case ID | Sample ID | Tissue Type | Tumor Descriptor | Specimen Type | Preservation Method |
|---|---|---|---|---|---|
| HCM-BROD-0009-C25-10A | HCM-BROD-0009-C25-10A | Normal | Not Applicable | Peripheral Blood NOS | Unknown |
| HCM-BROD-0009-C25-85A | HCM-BROD-0009-C25-85A | Tumor | Metastatic | 3D Organoid | Frozen |
| HCM-BROD-0009-C25-06A | HCM-BROD-0009-C25-06A | Tumor | Metastatic | Unknown | Frozen |
| HCM-BROD-0009-C25-10A | HCM-BROD-0009-C25-10A | Normal | Not Applicable | Peripheral Blood NOS | Unknown |
File Summary Page
Clicking on a file name, in the tables that appear on both the Repository and Cart pages, launches the File Summary Page. Each File Summary Page provides information about a data file, such as size, MD5 checksum, and data format; information on the type of data included; links to the associated cases and biospecimen; and information about how the data file was generated or processed.
The page also includes buttons to download the file, add it to the file cart, or (for BAM files) utilize the BAM slicing function.
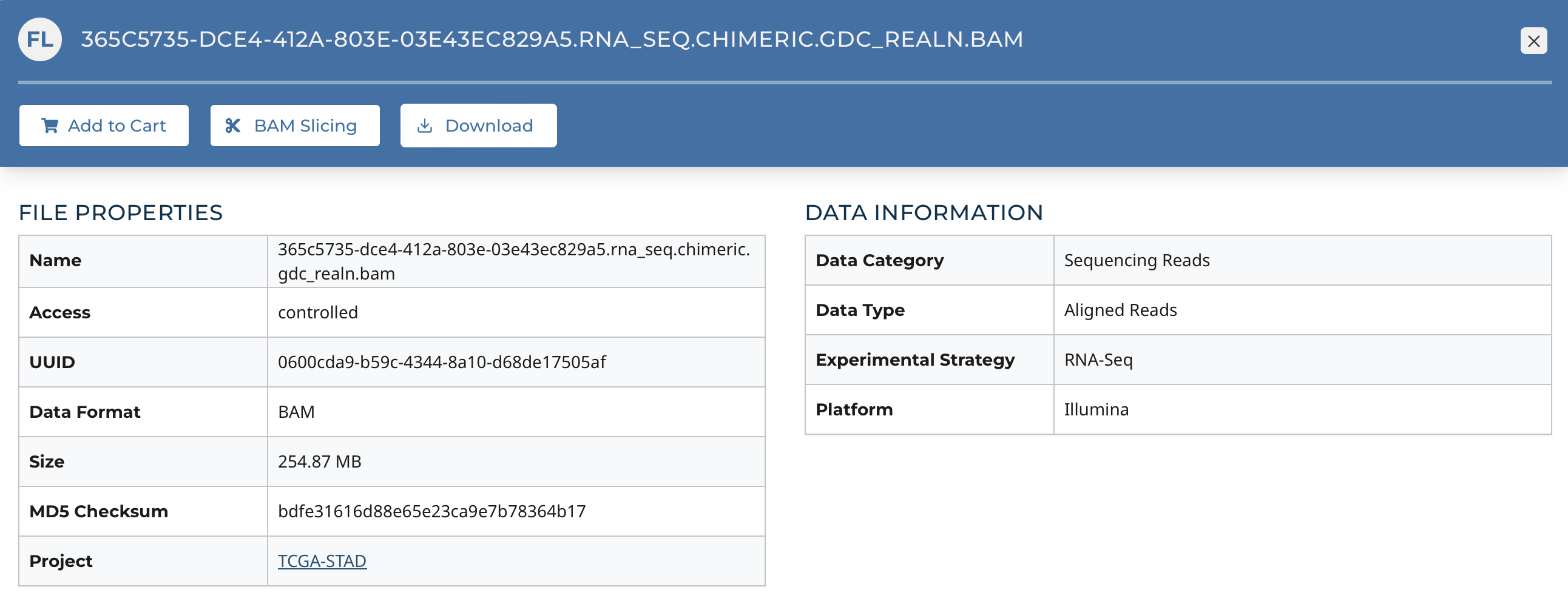
In the lower section of the screen, the following tables provide more details about the file and its characteristics:
- Associated Cases/Biospecimen: List of cases or biospecimen the file is directly attached to
- Analysis and Reference Genome: Information on the workflow and reference genome used for file generation
- Read Groups: Information on the read groups associated with the file
- Metadata Files: Experiment metadata, run metadata, and analysis metadata associated with the file
- Downstream Analysis Files: List of downstream analysis files
- File Versions: List of all versions of the file