Mutation Frequency
The Mutation Frequency tool visualizes the most frequently mutated genes and the most frequent somatic mutations for the active cohort. To launch the Mutation Frequency tool, click on its card from the Tools section of the Analysis Center.
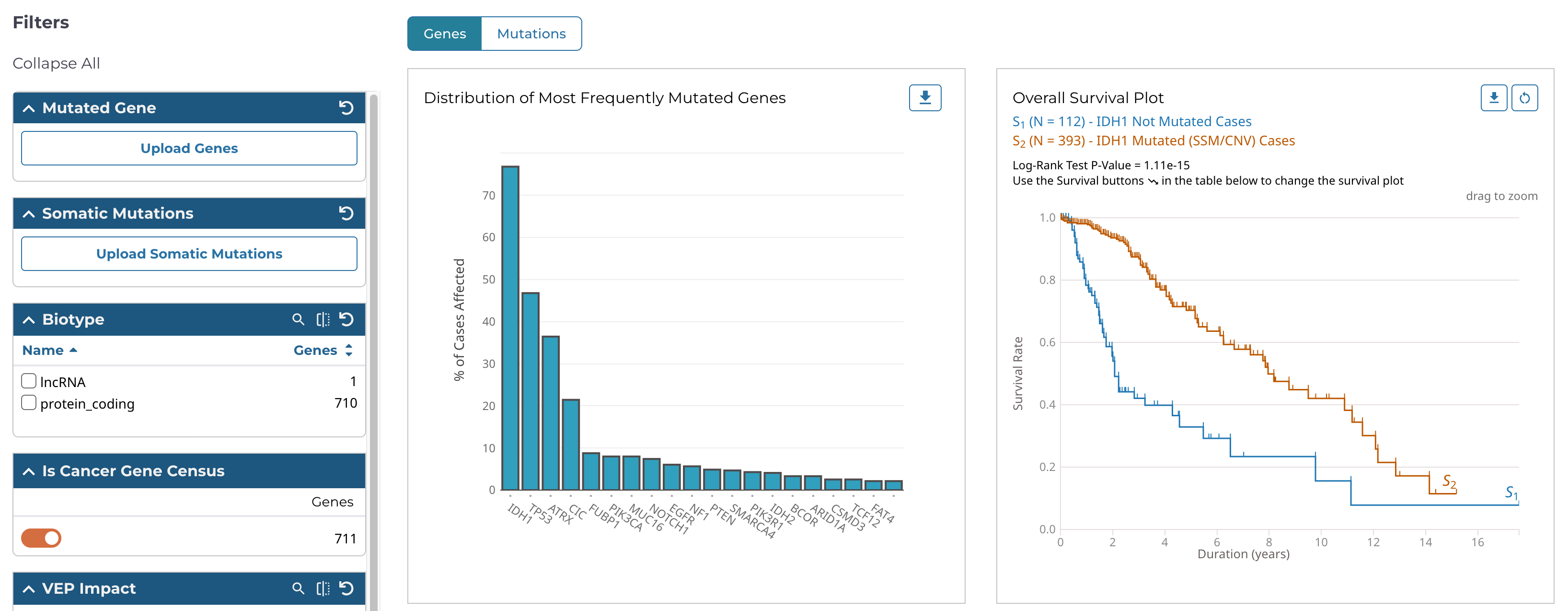
This tool includes the following visualizations:
Mutated Genes Histogram
The most frequently mutated genes are represented with a histogram that shows the percentage of cases affected within the active cohort. The histogram can be downloaded as an image (SVG/PNG) or raw data (JSON) using the button at the top right of the graphic.
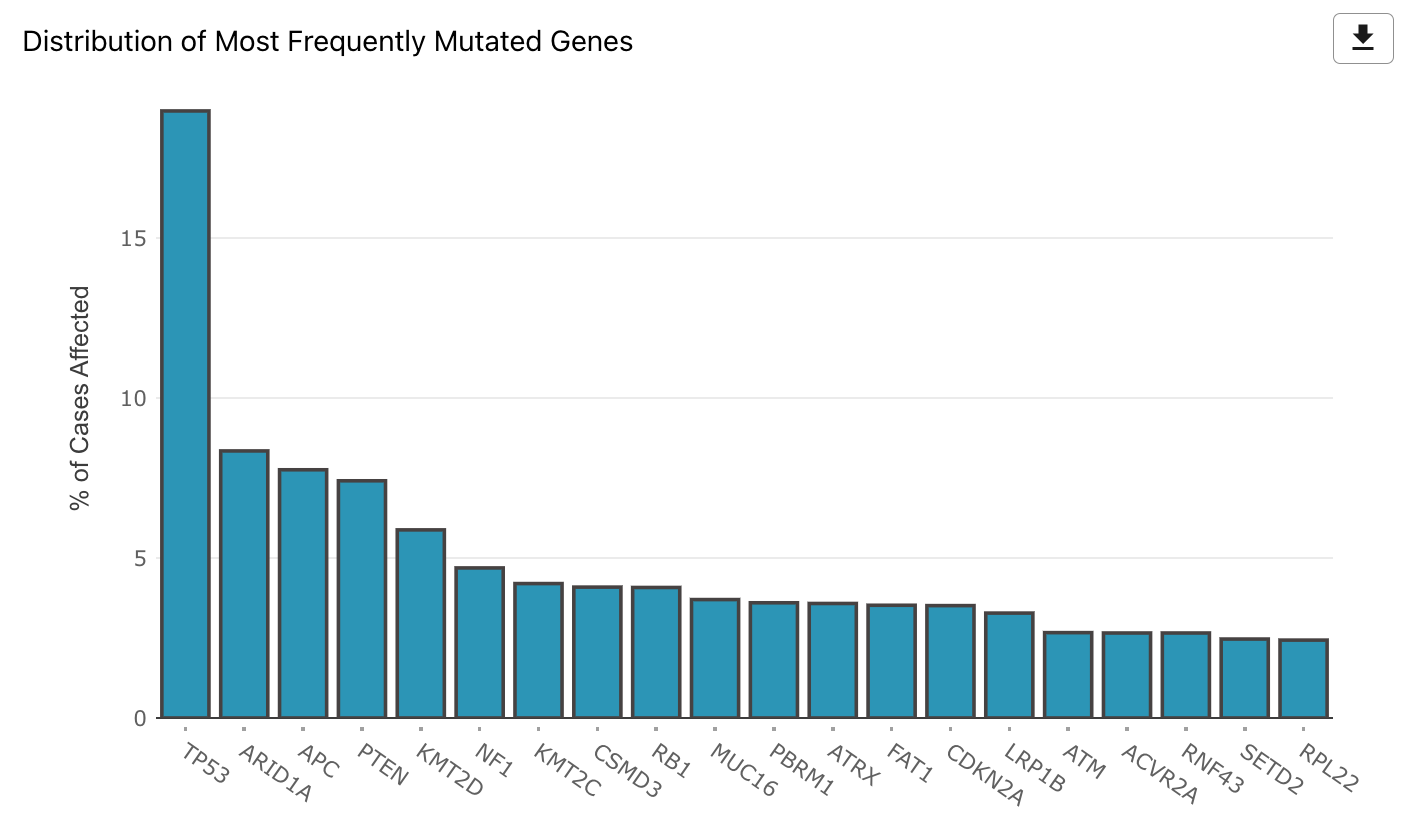
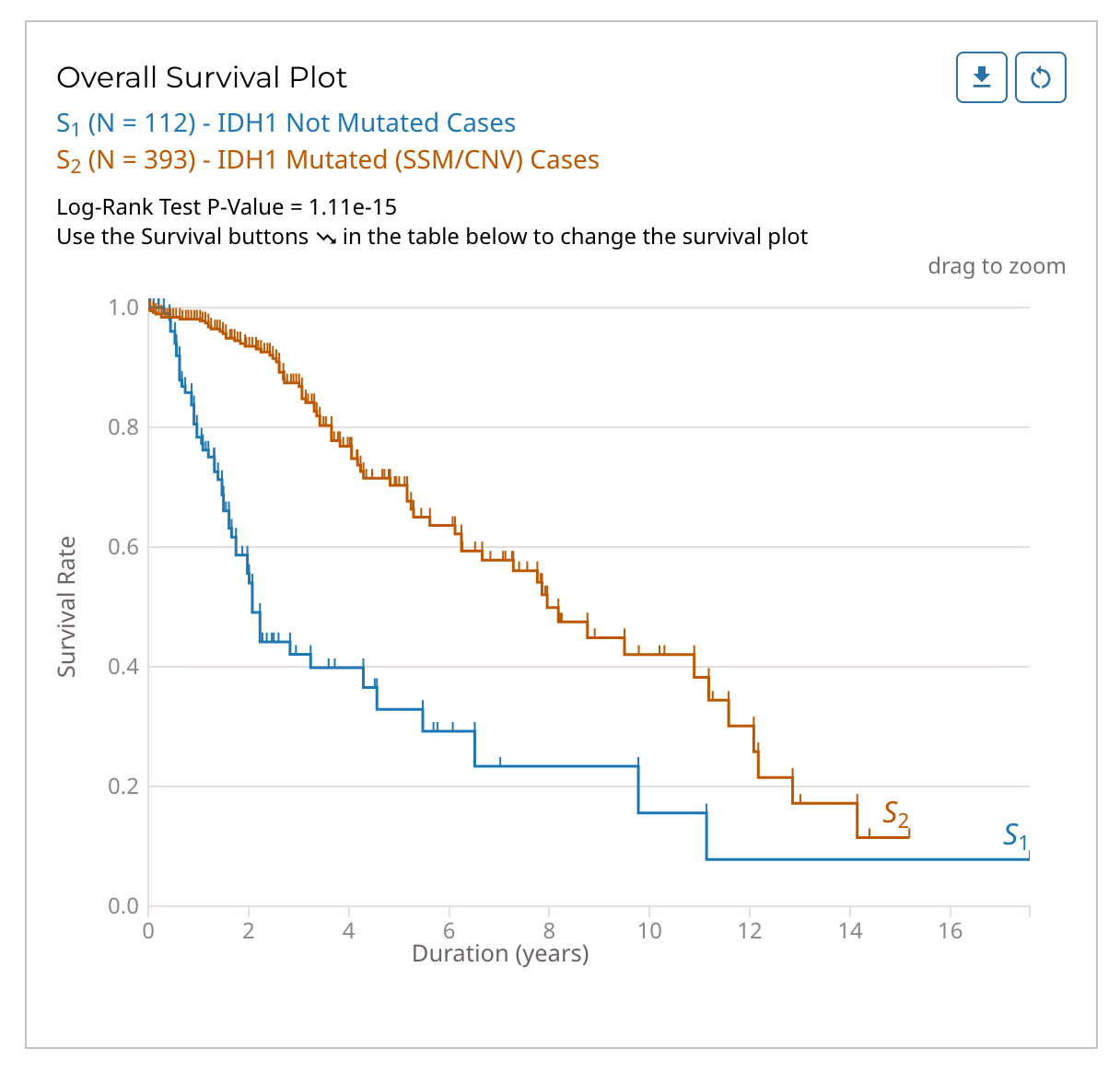
Survival Plot for Mutated Genes and Mutations
The mutation frequency survival plot is represented with two Kaplan-Meier curves based on cases with and without a specific mutation or mutated gene. Cases for both curves can be further filtered using the various filters available in the left panel of the Mutation Frequency tool. For example, selecting "high" for the VEP impact filter will limit the cases in both curves to those whose mutations have a high VEP impact.
The Log-Rank Test p-value is also displayed here. The survival plot can be downloaded as an image (SVG/PNG) or raw data (JSON/TSV) and the view can be reset using the buttons at the top right of the graphic.
Genes/Mutations Table
The genes/mutations table displays the most frequently mutated genes or the most frequent mutations in the active cohort by percent frequency in descending order. Additional columns show CNV information as well as the number of affected cases. The "Cohort" toggle can be used to filter the current cohort by a specific gene or mutation, and the "Survival" button allows the user to modify the survival plot. The red arrow button allows for the percentage of affected cases to be displayed on a project-level. The data displayed in the table can be exported as a TSV using the button at the top left of the table. Additional cohorts can be created using buttons located within the table.
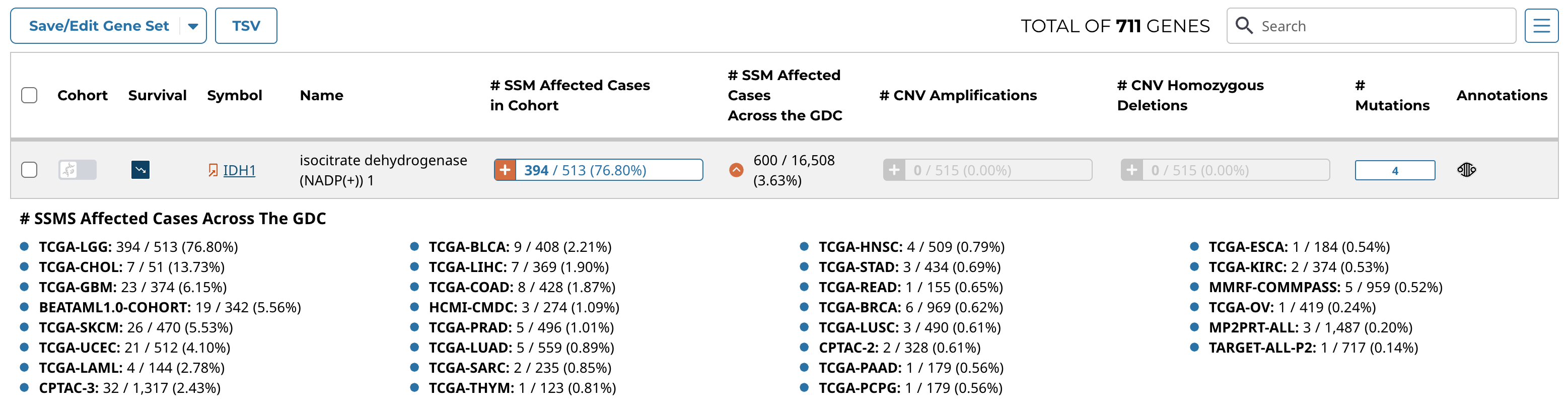
The table can be searched using the field at the top right of the table.

Additionally, clicking the button in the "# Mutations" column within the genes table will automatically apply a search for the corresponding gene in the mutations table. This is a convenient way to view the specific mutations in a given gene.
Gene and Mutation Summary Pages
Users can click on the Symbol links in the Genes Table and the DNA Change links in the Mutations Table to view the Gene and Mutation Summary Pages, respectively. These pages display information about specific genes and mutations, along with visualizations and data showcasing the relationship between themselves, the projects, and cases within the GDC. The gene and mutation data that is visualized on these pages are produced from the Open-Access MAF files available for download on the GDC Portal.
Gene Summary Pages describe each gene with mutation data and provide results related to the analyses that are performed on these genes.
Summary
The summary section of the gene page contains the following information:
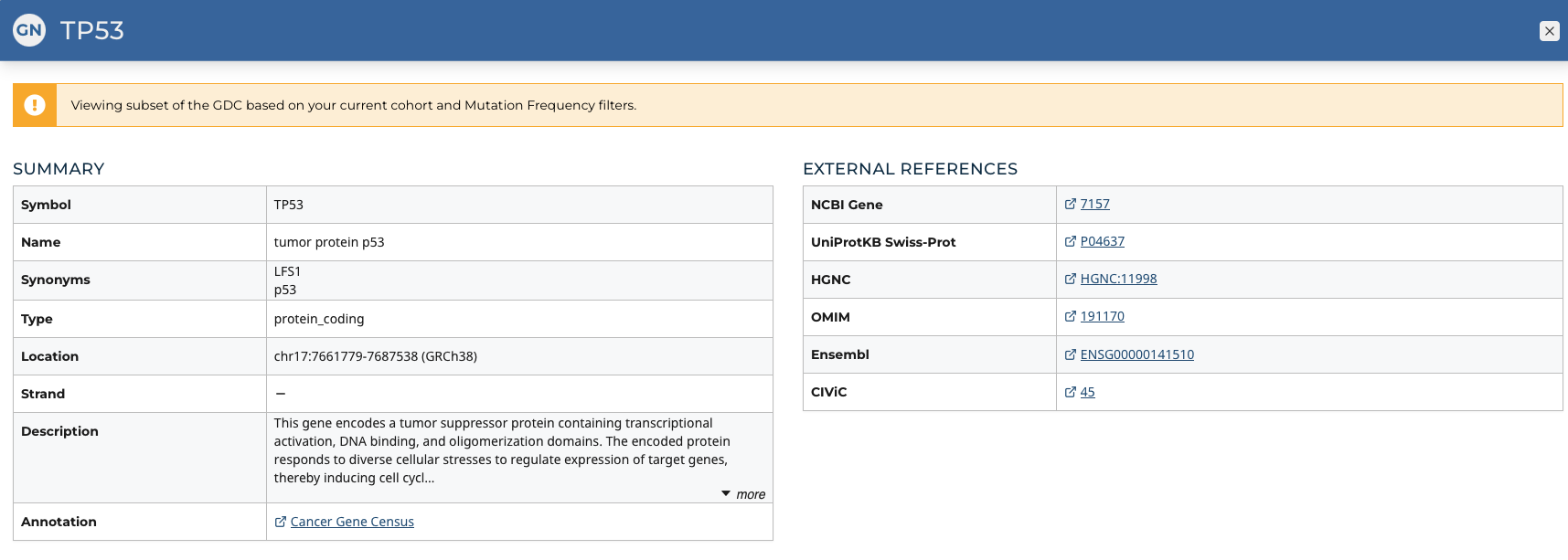
- Symbol: The gene symbol
- Name: Full name of the gene
- Synonyms: Synonyms of the gene name or symbol, if available
- Type: A broad classification of the gene
- Location: The chromosome on which the gene is located and its coordinates
- Strand: If the gene is located on the forward (+) or reverse (-) strand
- Description: A description of gene function and downstream consequences of gene alteration
- Annotation: A notation/link that states whether the gene is part of The Cancer Gene Census
External References
A list with links that lead to external databases with additional information about each gene is displayed here. These external databases include: Entrez, Uniprot, Hugo Gene Nomenclature Committee, Online Mendelian Inheritance in Man, Ensembl, CIViC, and GeneCards.
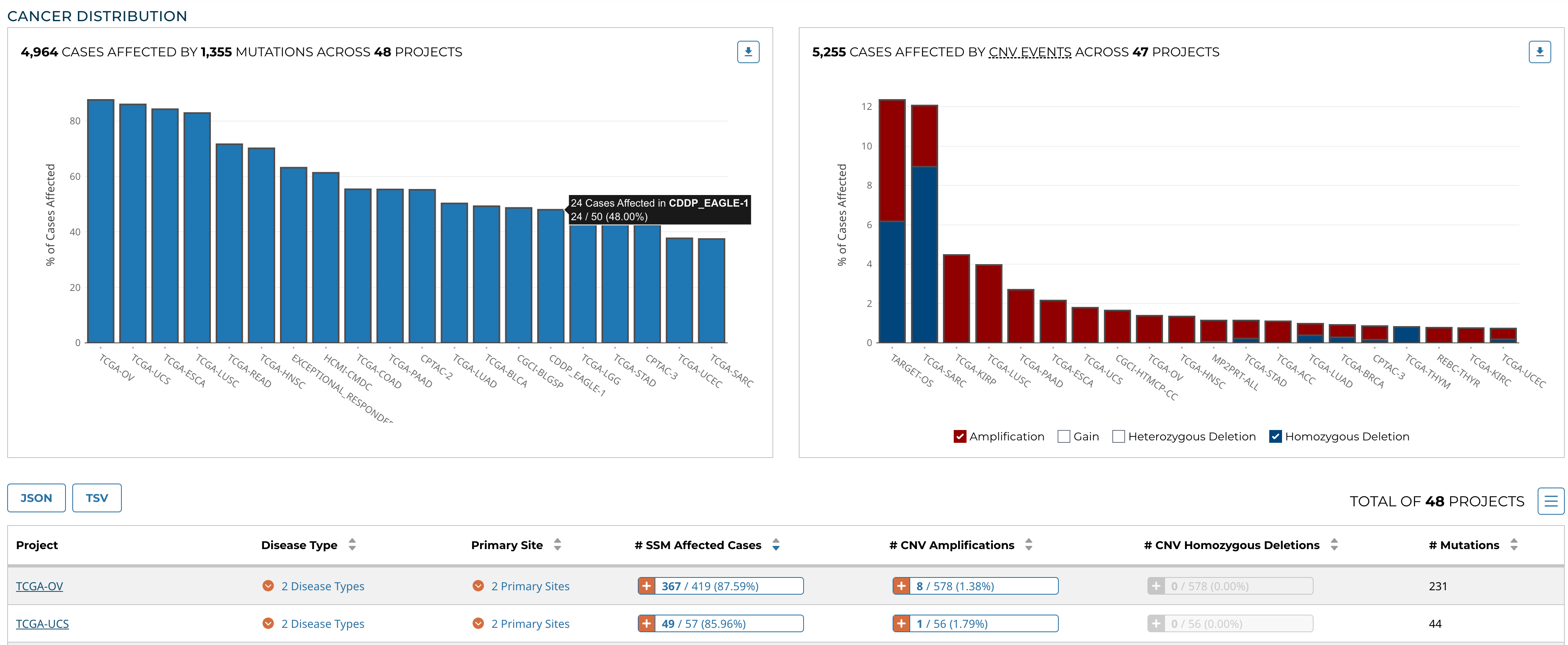
Cancer Distribution
A table and two bar graphs (one for mutations, one for CNV events) show how many cases are affected by mutations and CNV events within the gene as a ratio and percentage. Each row/bar represents the number of cases for each project. The final column in the table lists the number of unique mutations observed on the gene for each project.
Most Frequent Mutations
The 20 most frequent mutations in the gene are displayed as a bar graph that indicates the number of cases that share each mutation.
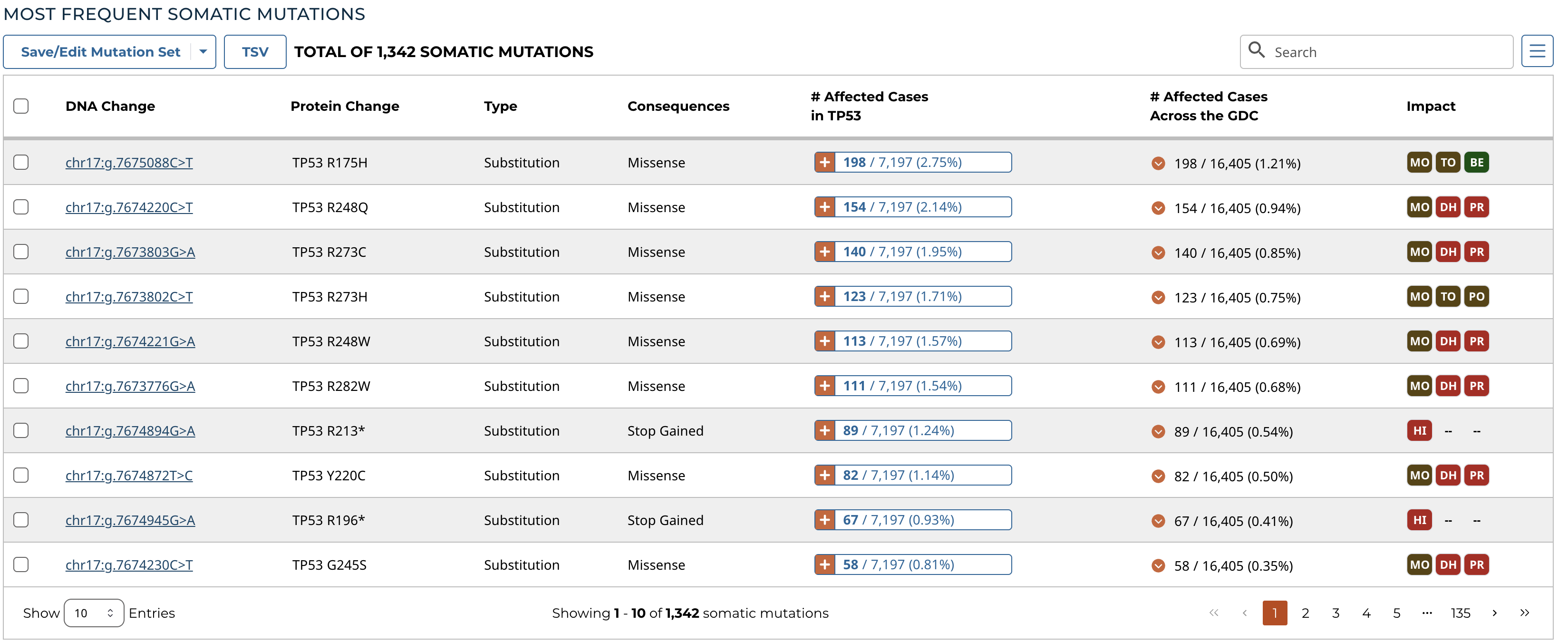
A table is displayed below that lists information about each mutation including:
- DNA Change: The chromosome and starting coordinates of the mutation are displayed along with the nucleotide differences between the reference and tumor allele
- Protein Change: The gene and amino acid change
- Type: A general classification of the mutation
- Consequences: The effects the mutation has on the gene coding for a protein (i.e. synonymous, missense, non-coding transcript)
- # Affected Cases in Gene: The number of affected cases, expressed as number across all mutations within the Gene
- # Affected Cases Across GDC: The number of affected cases, expressed as number across all projects. Choosing the arrow next to the percentage will expand the selection with a breakdown of each affected project.
- Impact: A subjective classification of the severity of the variant consequence. This is determined using Ensembl VEP, PolyPhen, and SIFT. The categories are outlined here.
Note: The Mutation UUID can be displayed in this table by selecting it from the Customize Columns button, represented by three parallel lines
The Mutation Summary Page contains information about one somatic mutation and how it affects the associated gene. Each mutation is identified by its chromosomal position and nucleotide-level change.
Summary
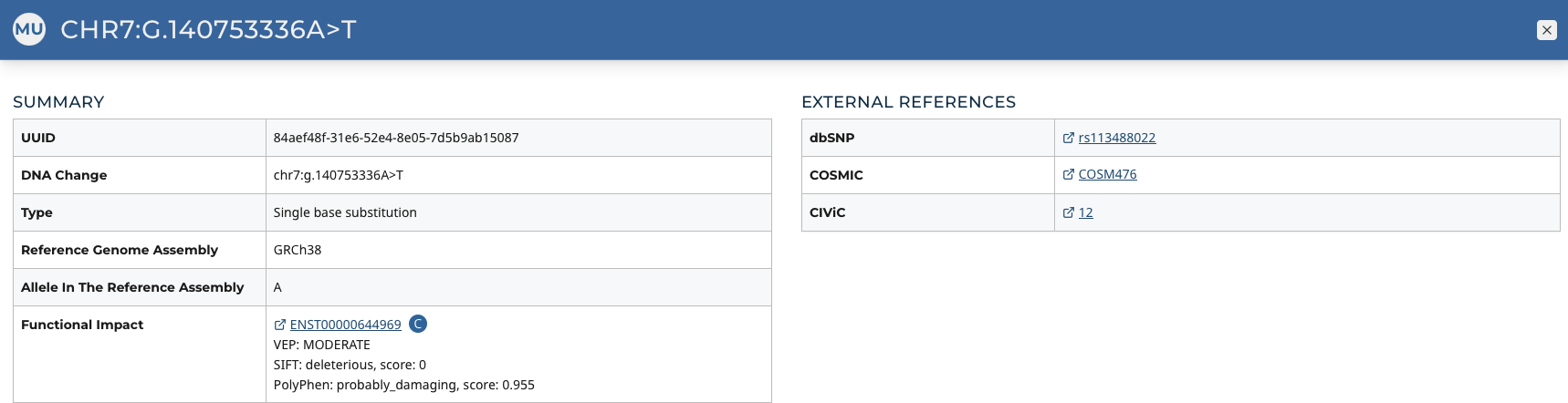
- UUID: A unique identifier (UUID) for this mutation
- DNA Change: Denotes the chromosome number, position, and nucleotide change of the mutation
- Type: A broad categorization of the mutation
- Reference Genome Assembly: The reference genome in which the chromosomal position refers to
- Allele in the Reference Assembly: The nucleotide(s) that compose the site in the reference assembly
- Functional Impact: A subjective classification of the severity of the variant consequence.
External References
A separate panel contains links to databases that contain information about the specific mutation. These include dbSNP, COSMIC, and CIViC.
Consequences
The consequences of the mutation are displayed in a table. The set of consequence terms, defined by the Sequence Ontology.
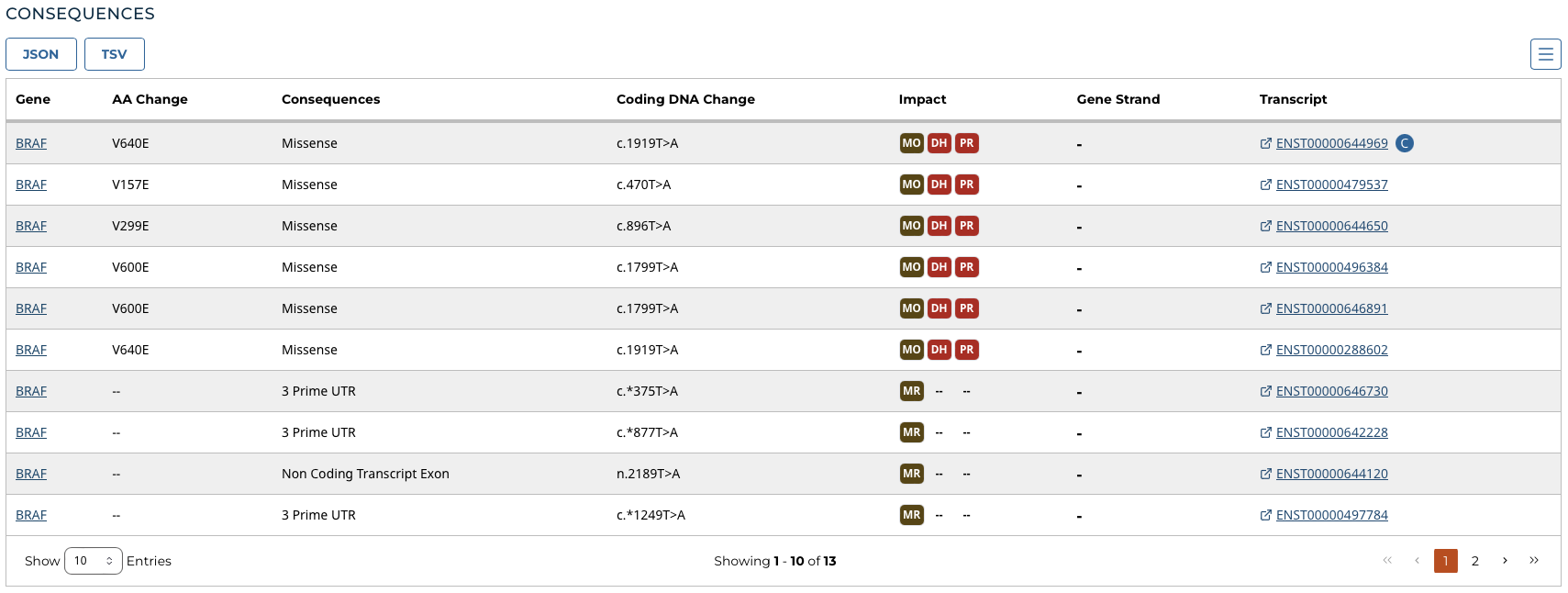
The fields that describe each consequence are listed below:
- Gene: The symbol for the affected gene
- AA Change: Details on the amino acid change, including compounds and position, if applicable
- Consequences: The biological consequence of each mutation
- Coding DNA Change: The specific nucleotide change and position of the mutation within the gene
- Impact: VEP, SIFT, and/or PolyPhen Impact ratings
- Gene Strand: If the gene is located on the forward (+) or reverse (-) strand
- Transcript: The transcript(s) affected by the mutation. Each contains a link to the Ensembl entry for the transcript
Cancer Distribution
A table and bar graph shows how many cases are affected by the particular mutation. Each row/bar represents the number of cases for each project.
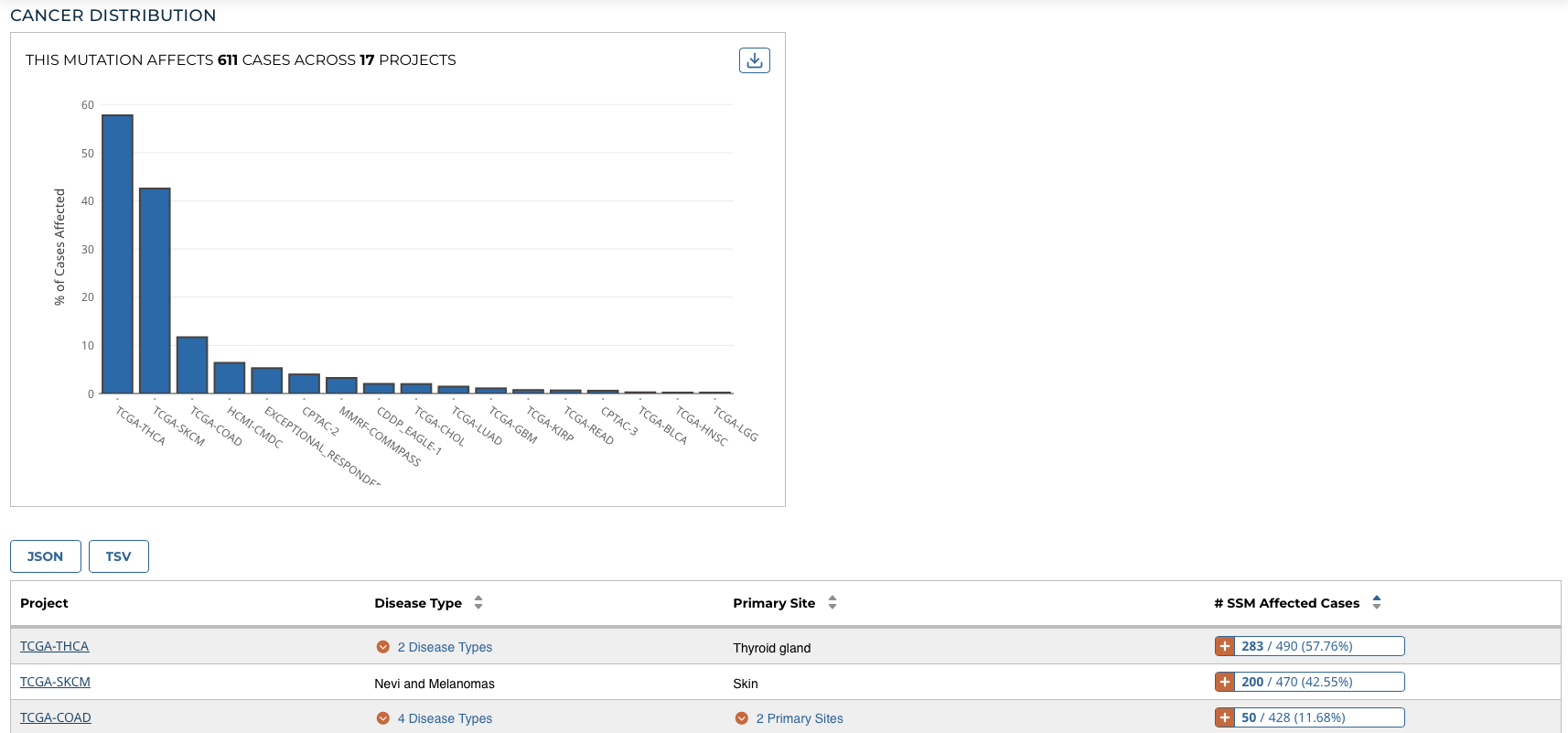
The table contains the following fields:
- Project: The ID for a specific project
- Disease Type: The disease associated with the project
- Primary Site: The anatomical site affected by the disease
- # SSM Affected Cases: The number of affected cases and total number of cases displayed as a fraction and percentage
Custom Mutated Genes and Somatic Mutation Filters

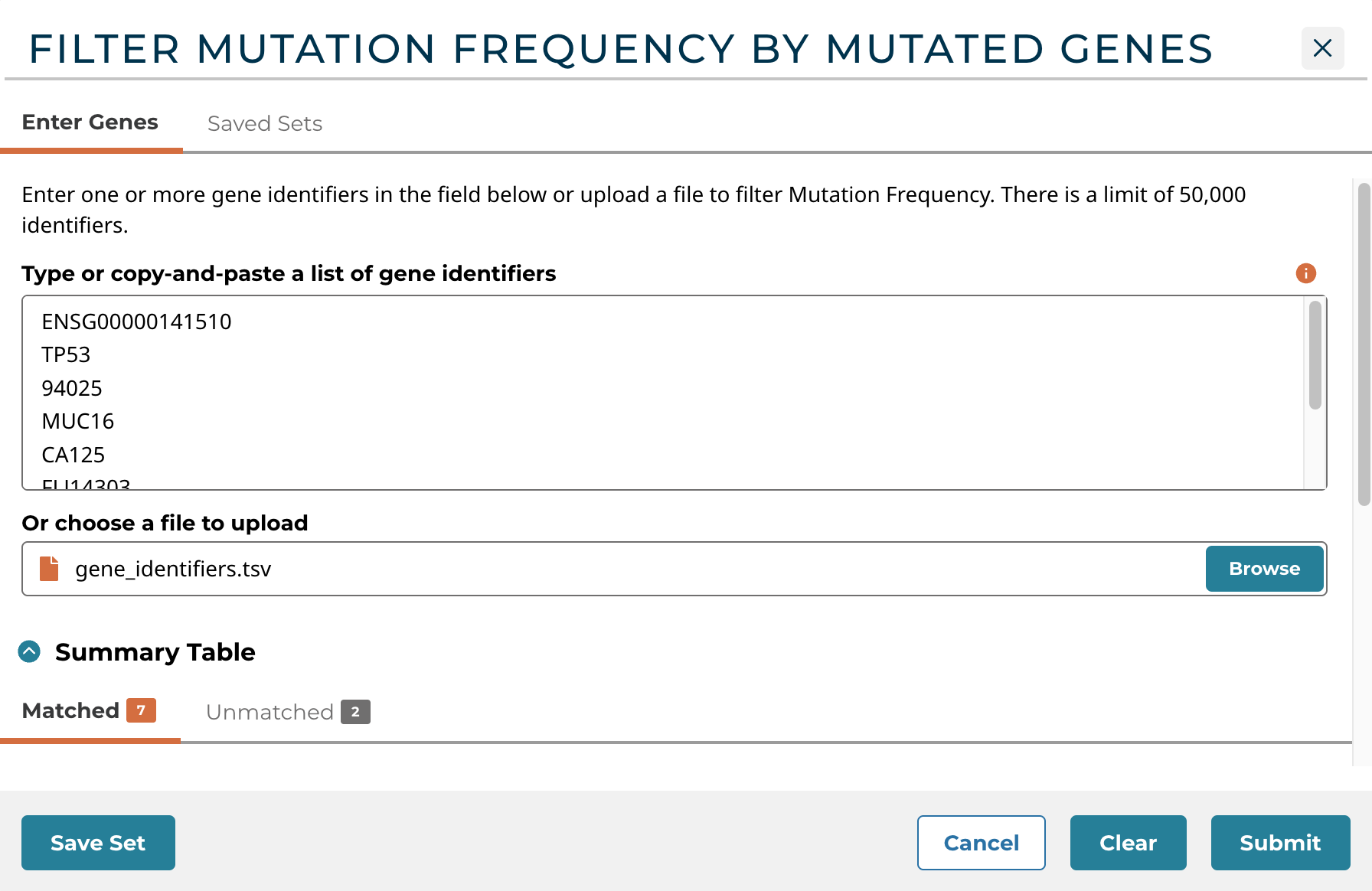
The Upload Genes button in the left panel of the Mutation Frequency tool allows users to filter mutation frequency by genes. Users can enter unique identifiers (i.e. gene symbols, gene IDs, etc.) directly into the text box as a plain text list or upload a list of unique identifiers as a CSV, TSV, or TXT file. Users can hover over the orange (i) to verify accepted gene identifiers, delimiters, and file formats.
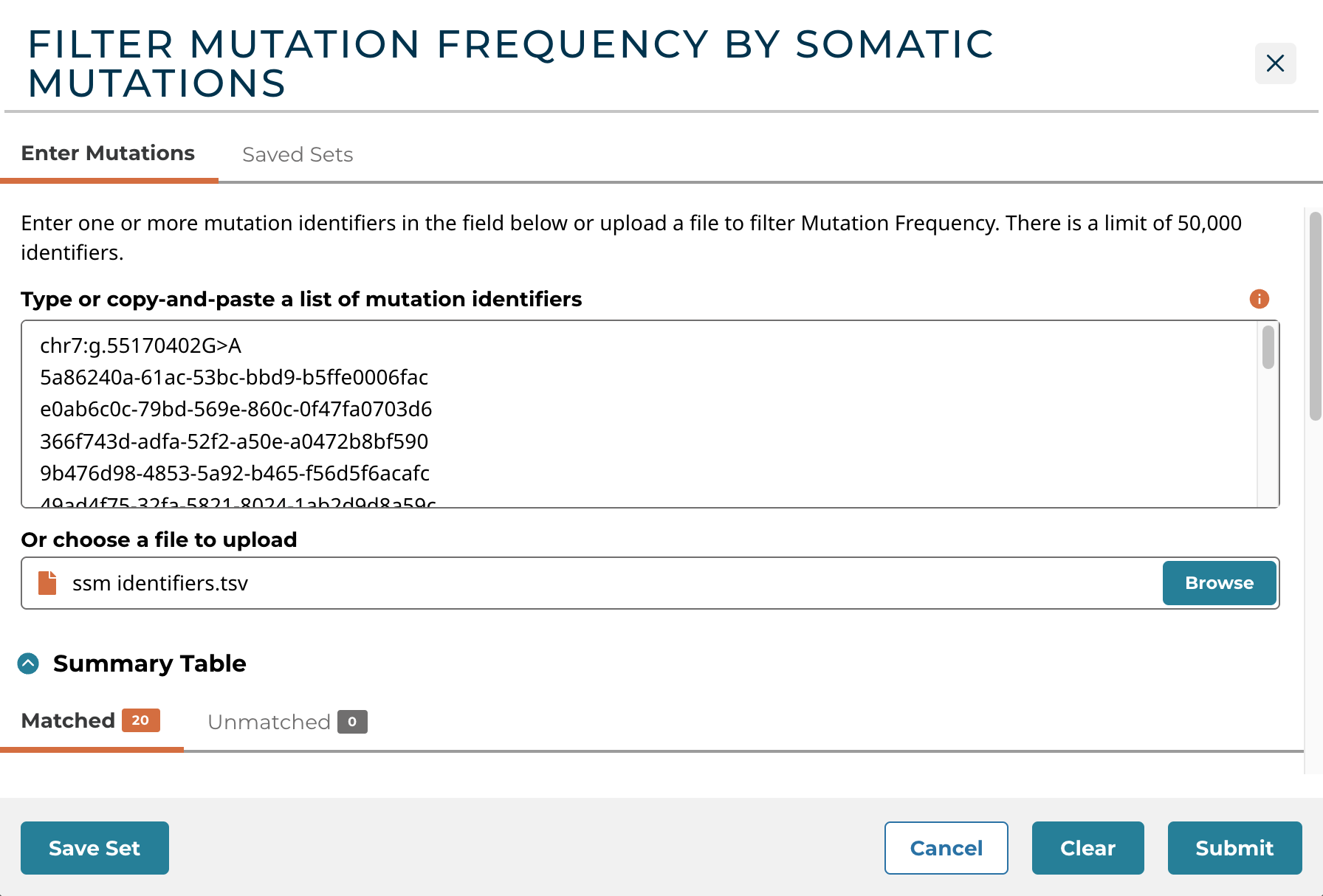
The Upload Somatic Mutations button allows users to filter mutation frequency by mutations. Users can enter unique identifiers (i.e. mutation UUIDs, etc.) directly into the text box as a plain text list or upload a list of unique identifiers as a CSV, TSV, or TXT file. Users can hover over the orange (i) to verify accepted mutation identifiers, delimiters, and file formats.
Mutation Frequency Facet Filters
A set of frequently-used properties are available to filter genes and mutations in the left panel of the Mutation Frequency tool. Using each of these filters will dynamically change the graphics and table to represent the filtered data.
- Biotype: Classification of the type of gene according to Ensembl. The biotypes can be grouped into protein coding, pseudogene, long noncoding and short noncoding. Examples of biotypes in each group are as follows:
- Protein coding: IGC gene, IGD gene, IG gene, IGJ gene, IGLV gene, IGM gene, IGV gene, IGZ gene, nonsense mediated decay, nontranslating CDS, non stop decay, polymorphic pseudogene, TRC gene, TRD gene, TRJ gene, TRV gene.
- Pseudogene: Disrupted domain, IGC pseudogene, IGJ pseudogene, IG pseudogene, IGV pseudogene, processed pseudogene, transcribed processed pseudogene, transcribed unitary pseudogene, transcribed unprocessed pseudogene, translated processed pseudogene, translated unprocessed pseudogene, TRJ pseudogene, TRV pseudogene, unprocessed pseudogene.
- Long noncoding: 3 prime overlapping ncrna, ambiguous orf, antisense, antisense RNA, lincRNA, macro lincRNA, ncrna host, processed transcript, sense intronic, sense overlapping.
- Short noncoding: miRNA, miRNA pseudogene, miscRNA, miscRNA pseudogene, Mt rRNA, Mt tRNA, rRNA, scRNA, snlRNA, snoRNA, snRNA, tRNA, tRNA pseudogene, vaultRNA.
- Is Cancer Gene Census: Whether or not a gene is part of The Cancer Gene Census. Note that this is switched on as a default.
- Impact: A subjective classification of the severity of the variant consequence. These scores are determined using the following three tools:
- VEP:
- HIGH (H): The variant is assumed to have high (disruptive) impact in the protein, probably causing protein truncation, loss of function or triggering nonsense mediated decay
- MODERATE (M): A non-disruptive variant that might change protein effectiveness
- LOW (L): Assumed to be mostly harmless or unlikely to change protein behavior
- MODIFIER (MO): Usually non-coding variants or variants affecting non-coding genes, where predictions are difficult or there is no evidence of impact
- PolyPhen:
- probably damaging (PR): It is with high confidence supposed to affect protein function or structure
- possibly damaging (PO): It is supposed to affect protein function or structure
- benign (BE): Most likely lacking any phenotypic effect
- unknown (UN): When in some rare cases, the lack of data does not allow PolyPhen to make a prediction
- SIFT:
- tolerated: Not likely to have a phenotypic effect
- tolerated_low_confidence: More likely to have a phenotypic effect than 'tolerated'
- deleterious: Likely to have a phenotypic effect
- deleterious_low_confidence: Less likely to have a phenotypic effect than 'deleterious'
- VEP:
- Consequence Type: Consequence type of this variation; sequence ontology terms
- Type: A general classification of the mutation
Saving a Gene or Mutation Set
After filtration, a set of genes or mutations can be saved by choosing the "Save/Edit Gene Set" or "Save/Edit Mutation Set" button at the top left of the table.