Sequence Reads Tool
Introduction to Sequence Reads Visualization
Sequence Reads is a web-based tool that uses the ProteinPaint BAM track and NCI Genomic Data Commons (GDC) BAM Slicing API to allow users to visualize read alignments from a BAM file. Given a variant (i.e. Chromosome number, Position, Reference Allele and Alternative Allele), the Sequence Reads tool can classify reads supporting the reference and alternative allele into separate groups.
Quick Reference Guide
At the Analysis Center, click on the 'Sequence Reads' card to launch the app.

This feature requires access to controlled data, which is maintained by the Database of Genotypes and Phenotypes (dbGaP) See Obtaining Access to Controlled Data. In order to use this tool, users must be logged in with valid credentials. Otherwise, users will be prompted to login.
Selecting BAM Files and Variants
Once logged in, the Sequence Reads tool will display a search bar, as well as a link below the search bar to browse the first 1,000 available BAM files for the active cohort. Users can choose to select a BAM from the available list, or search for a specific BAM file by entering four types of inputs: file name, file UUID, case ID, or case UUID.
The tool will verify the query string and return all matching GDC BAM files in a table, from which the user can select one or multiple to use with the tool.

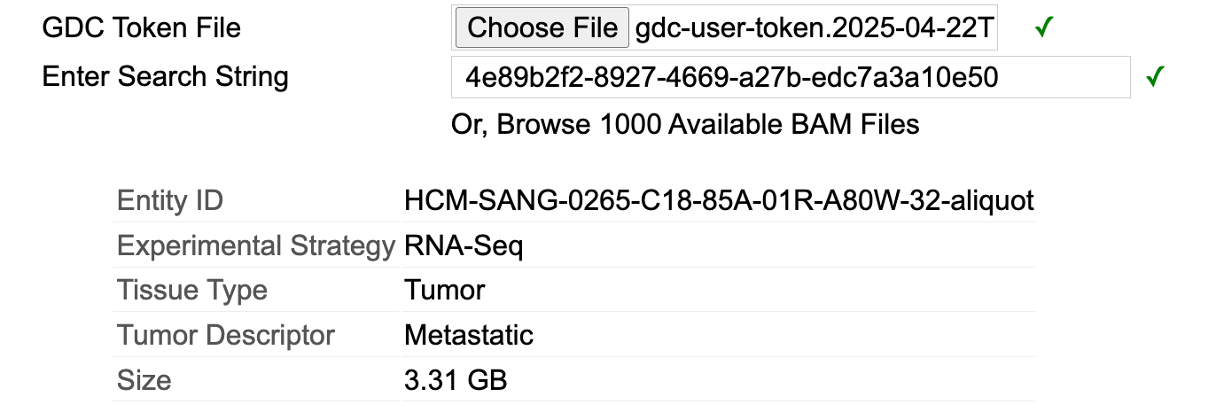
If an exact match is entered (i.e. a file name or file UUID), the Sequence Reads tool will find that BAM and present brief information about the file.
In the subsequent section, the mutation table displays somatic mutations catalogued by the GDC for this case, if available. Users can select a mutation to visualize read alignments on this variant.

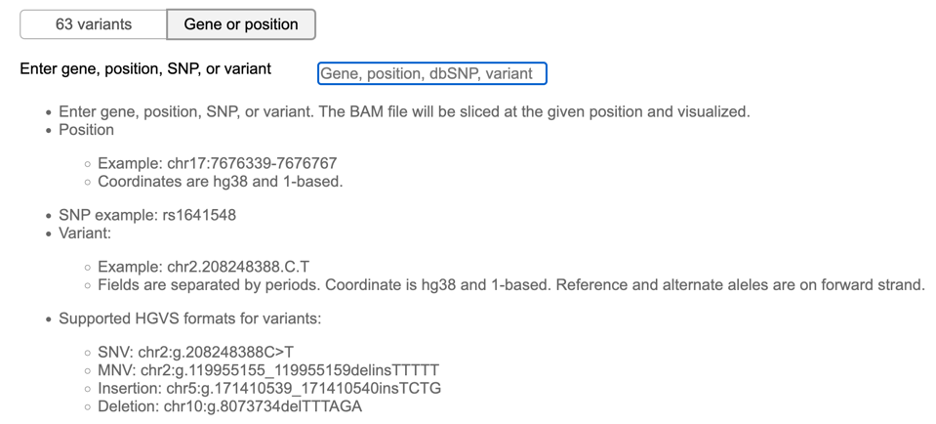
Alternatively, the Gene or position button at the top of the mutation table allows users to enter a custom genomic region for BAM visualization.
Once at least one BAM file is selected and a gene, position, SNP, or variant is entered, the Sequence Reads tool will display the BAM visualization.
Toolbar
- Current Position in Genome: Displays the coordinates of the region currently displayed
- Reference Genome Build: Refers to the genome build that was used for mapping the reads; the GDC uses Reference Genome Build 38 (hg38)
- Zoom Buttons: Zooms in (
In) or out (Out x2,x10, andx50) of the current view
Reference Genome Sequence
The Reference Genome Sequence displays the reference genome build against which the reads have been aligned.
Gene Models
The Genome Models row displays the gene model structure from the view range. When zoomed into a coding exon, the letters correspond to the 1-letter amino acid code for each amino acid and are placed under its corresponding 3-letter nucleotide codon under the reference genome sequence. The arrows describe the orientation of the strand of the gene model being displayed (right arrow for forward strand and left arrow for reverse strand).
Graphical representations of the reads are displayed as they are aligned on the chromosome. Sequence can be read when zoomed in.
ProteinPaint BAM Track
Pileup Plot
The Pileup Plot shows the total read depth at each nucleotide position of the region being displayed.

Read Alignment Plot
This visual contains the main read alignment plot of the reads from the BAM file.
When completely zoomed out, base-pair quality of each nucleotide in each read is not displayed. Users can zoom into the plot via the toolbar or by dragging on the genomic ruler (a) to zoom into the selected region (b).
Clicking on a read in the plot launches a window that displays the alignment between the read and reference sequence, as well as the chromosome, coordinates, read length, template length, CIGAR score, flag, and name. If the read is paired, the position of the other segment will be displayed below. This pop-up also contains two buttons, Copy read sequence and Show gene model, which copy the nucleotide sequence of the read to the computer clipboard and display the gene model, respectively.

Mutation Rendering
Mutations are rendered as follows:
-
Insertion: The alphabet representing the nucleotides is displayed between the two reference nucleotides in cyan color, with the shade scaled by base quality
- If more than one nucleotide is inserted, a number is printed between the two reference nucleotides indicating the number of inserted nucleotides
- Clicking the read with multiple insertions will display the complete inserted nucleotide sequence

-
Deletion: A black line represents the span of deleted bases

-
Substitution or Mismatch: The substituted nucleotide is highlighted in red background, with the shade of red scaled by base quality

-
Splicing: The different fragments of a read separated due to splicing are joined by a gray line
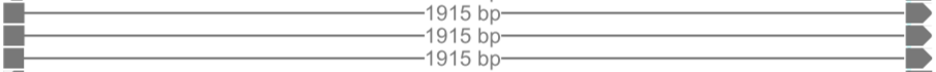
Color Coding of Reads
Color codes in the background of the read describe the quality of the read alignment and its mate (in case of paired-end sequencing). These colors are assigned both on the basis of the CIGAR sequence (if it contains a softclip) and the flag value of both the read and its mate.
- Gray: Suggests that both the read (at least part of it) and its mate are properly aligned and the insert size is within expected range
- Blue: Indicates that part of the read is soft clipped
- Brown: Indicates that the mate of the read is unmapped
- Green: Indicates that the template has the wrong insert size
- Pink: Indicates that the orientation of the read and its mate is not correct
- Orange: Indicates the read and its mate are mapped in different chromosomes
BAM Track Configuration Panel
The BAM Track Configuration Panel, which can be accessed by clicking the CONFIG option next to the Pileup plot, provides buttons for toggling between single-end and paired-end mode.

In single-end display each read is displayed individually without displaying any connections with its respective mate. In case of the paired-end display the two paired reads are joined by a gray dotted-line if the coordinates of the two reads do not overlap. When the coordinates of the two read-pairs overlap, the overlapped region is highlighted by a blue line.
The BAM Track Configuration Panel also provides a check box to show/hide PCR and optical duplicated reads.
Launch the Sequence Reads Tool
At the Analysis Center, click on the "Sequence Reads" card to launch the app.
A user needs to be logged in to use this feature. If not, the user will be prompted to log in. Once the user logs in, a search bar and submit button will appear as below.

Find and Display BAM Files in GDC
To find a BAM file in GDC, a user can enter four types of inputs including file name, file UUID, case ID, or case UUID. The tool will verify the query string and return matching BAM files.
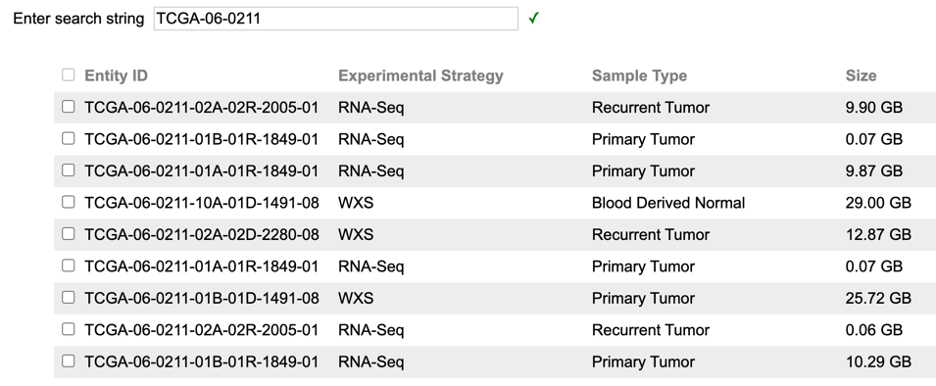
As an example, using case ID "TCGA-06-0211" will return 9 BAM files available from this case displayed in a table. One or multiple BAM files from this table must be selected to proceed.
When a file name or UUID is provided, it will display brief information about the file. A user does not need to select anything here as the file is automatically selected.
The subsequent section displays somatic mutations catalogued by GDC for this case, if available. A user can select a mutation to visualize read alignment on this variant.
Alternatively, a user can enter a custom genomic region for BAM visualization. At the toggle button on top of the mutation table, click the "Gene or position" option to show the gene search box.
Follow the instructions to enter gene, position, SNP, or variant. Press ENTER to validate the input.
Lastly, press the "Submit" button to view read alignment from the selected BAM file over the selected mutation or genomic region. The server will verify the user's access to the requested BAM file and query the GDC API to slice the BAM file at the selected region. This may take from 10 seconds to a minute.
An error message will appear if the user does not have access to the requested BAM file. Please follow the instructions to obtain access.

Once the BAM visualization is successfully displayed, the search interface is hidden, and a button named "Back to input form" is shown. Clicking the button will bring the user back to the search interface so a user can change the BAM file or mutation.

Click the "Download GDC BAM Slice" button to download the BAM slice file used in this visualization.
Using ProteinPaint Genome Browser
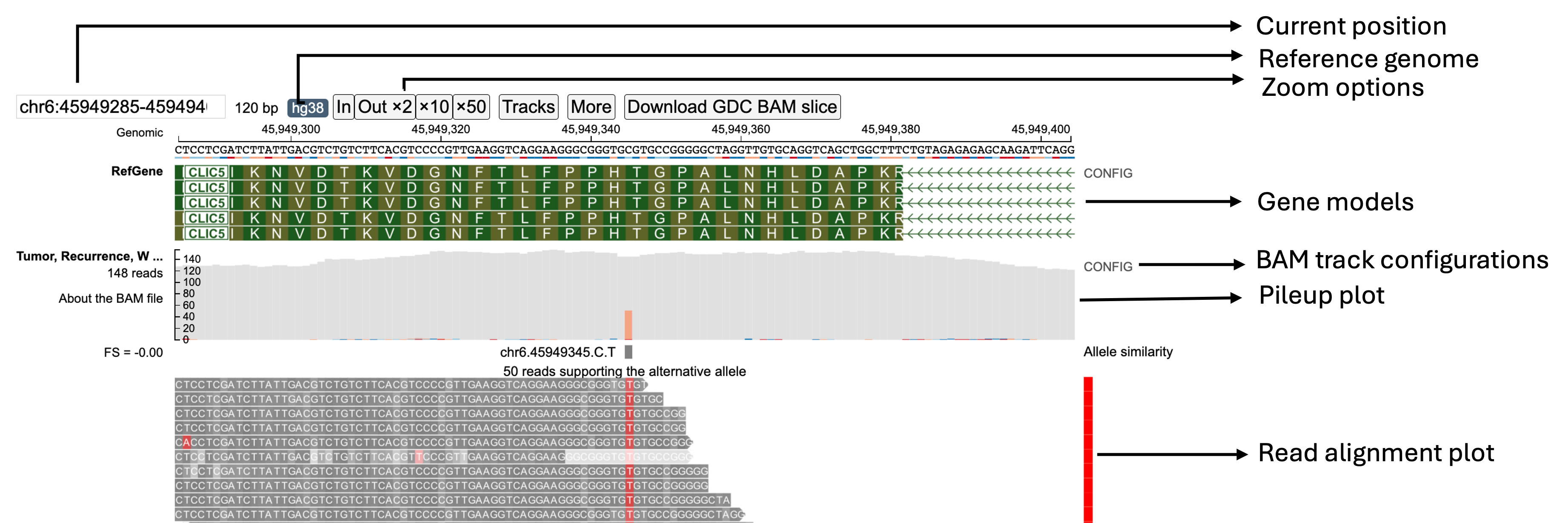
Various fields labeled in the above figure are described below:
Current Position in Genome
The Current Position in Genome text box displays the coordinates of the region currently displayed on the screen. It initially shows the coordinates specified in the URL. On pan/zoom by the user, this region displays the updated coordinates of the view region.
Reference Genome Build
The Reference Genome Build button refers to the genome build specified by the user that was used for mapping the reads. The GDC uses Reference Genome Build 38 (hg38).
Zoom Buttons
A user can zoom in/out of the current view by clicking the "In" (zoom in) or "Out x2" (zoom out) buttons. By clicking on the x10 and x50 button, a user can zoom out 10 and 50-fold respectively. Alternatively, a user may choose to zoom into a smaller region by dragging on the genomic ruler (a) to zoom into the selected region (b) as shown below.
Reference Genome Sequence
The Reference Genome Sequence displays the reference genome build against which the reads have been aligned.
Gene Models
This Genome Models row displays the gene model structure from the view range. When zoomed into a coding exon, the letters correspond to the 1-letter amino acid code for each amino acid and are placed under its corresponding 3-letter nucleotide codon under the reference genome sequence. The arrows describe the orientation of the strand of the gene model being displayed (right arrow for forward strand and left arrow for reverse strand).
ProteinPaint BAM Track Features
Pileup Plot
The Pileup Plot shows the total read depth at each nucleotide position of the region being displayed. Color codes of bars represent various possibilities:
Gray - Reference allele nucleotides Blue - Soft clipped nucleotides Mismatches: * nucleotide "A" - Red (color code: #ca0020) * nucleotide "T" - Orange (color code: #f4a582) * nucleotide "C" - Light blue (color code: #92c5de) * nucleotide "G" - Dark blue (color code: #0571b0)
Read Alignment Plot
The Read Alignment Plot contains the main read alignment plot of the reads from the BAM file.
Rendering of Various Mutations
Insertion
In case of a single nucleotide insertion, the alphabet representing the nucleotide (A/T/C/G) is displayed between the two reference nucleotides in cyan color.

Darkness of the inserted nucleotide is determined by the base quality, as an example below of an inserted T with low quality.

If more than one nucleotide is inserted, a number is printed between the two reference nucleotides indicating the number of inserted nucleotides. The text color is full cyan and does not account for the quality of inserted bases. Showing below is a read with two insertions, first with 2 bases, and second with T.

On clicking this read, the read information panel is displayed where the complete inserted nucleotide sequence is shown in cyan color.
Deletion
A black line represents the span of deleted bases.
Substitution (or Mismatch)
In case of substitutions (or mismatches), the substituted nucleotide ("A") is highlighted in red background, with the shade of red scaled by base quality.
Splicing
In case of splicing, the different fragments of a read separated due to splicing are joined by a gray line as shown below. In the example below, the reads contain spliced fragments that are separated by a 1915bp intron.
Zooming the Read Alignment Plot
The rendering of the reads depends upon the zoom level (horizontal zoom) chosen by the user and the number of reads mapped at the display region (vertical zoom).
Horizontal Zoom
The BAM track has three levels of horizontal zoom:
Overview Level
This is the completely zoomed out mode (shown below). At this resolution, base-pair quality of each nucleotide in each read is not displayed as each read occupies a very small area on the screen. Also the reference sequence at the top is not displayed. Only reads which contain big insertions/deletions/softclips or are discordant are represented by their respective colors. Also see the section on color codes of reads.
Base-pair Quality Level
On zooming in to sufficient level, in addition to color codes of reads, the phred base pair quality score of each read is also displayed. Poor base-pair quality of nucleotides is represented by lighter shades of the respective color and darker shades represent high base-pair quality. For example, dark gray color represents a higher quality nucleotide in a properly mapped read than light gray which represents poor base-pair quality.
Base-pair Resolution Level
At this resolution, all information including the read sequence of each read is displayed along with reference genome nucleotides at the top.
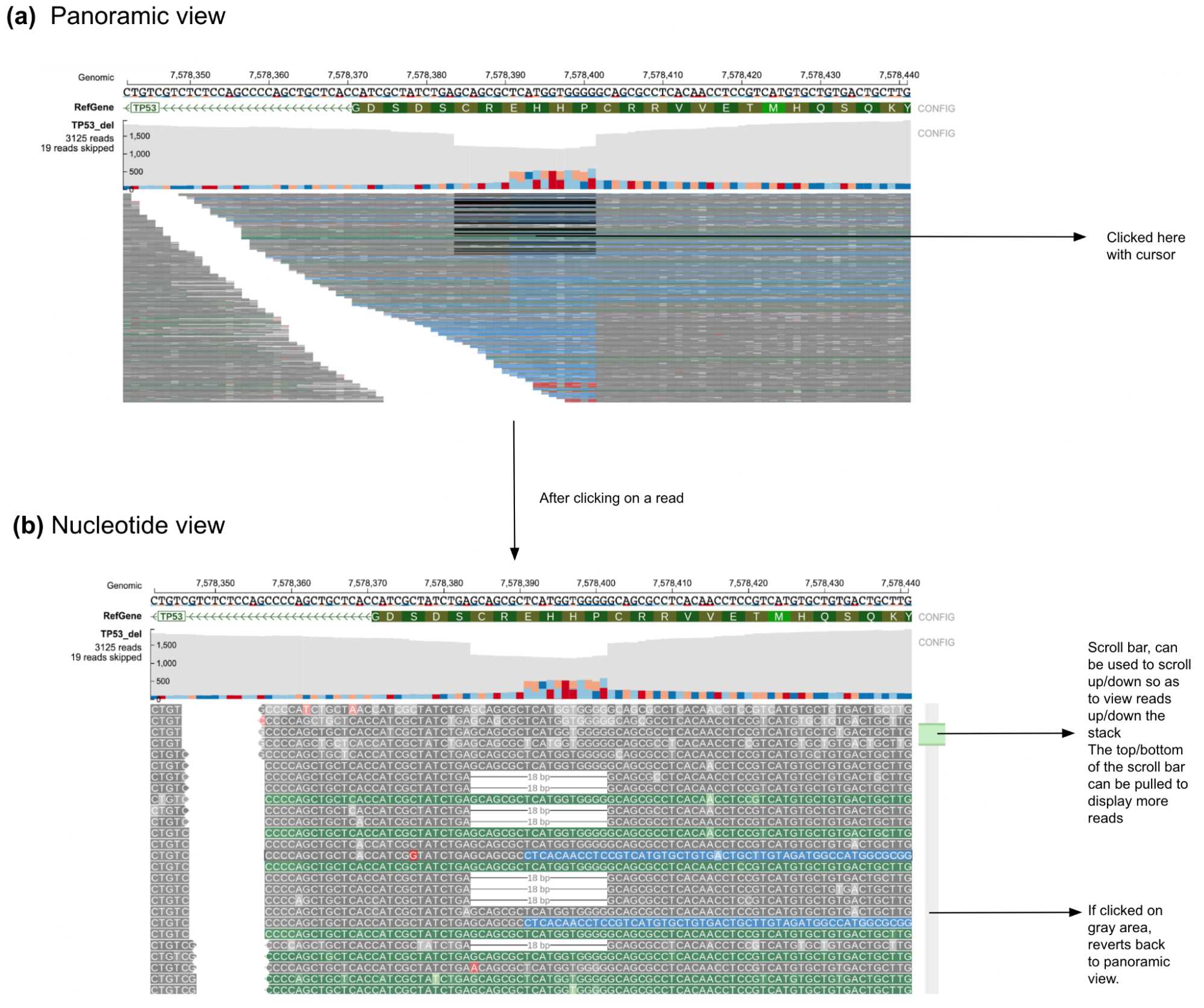
Vertical Zoom: Examining Subset of Reads
ppBAM can display up to 7000 reads, and will downsample if the number of reads in a region is over 7000. This is especially helpful for displaying high-depth sequencing data. However, displaying nucleotides from each read for such a large number of reads is not feasible. Therefore, the pixel width of each read is reduced to accommodate all reads in the region (Panoramic view, figure below). When the user clicks on a read, that part of the alignment stack is enlarged to show the nucleotides within each read (Nucleotide view, figure below) stacked near the cursor click. Reads at the top and bottom of the stack can be viewed by scrolling up/down with the scroll-bar. The top/bottom of the green scroll-bar can be adjusted to display more reads on the screen by reducing the individual width of each read. On clicking the gray area of the scroll bar region, the panoramic view is displayed again.
BAM Track Configuration Panel
The BAM Track Configuration Panel can be accessed by clicking the "CONFIG" option next to the pileup plot. The BAM Track Configuration Panel (shown below) provides buttons for toggling between single-end and paired-end mode. It also provides a check box to show/hide PCR and optical duplicated reads.
BAM track configuration panel figure
Single and Paired-end Read
The configuration panel provides a toggle to change view between single-end (default) and paired-end view. In single-end display each read is displayed individually without displaying any connections with its respective mate. In case of the paired-end display the two paired reads are joined by a gray dotted-line if the coordinates of the two reads do not overlap. When the coordinates of the two read-pairs overlap, the overlapped region is highlighted by a blue line.
The following shows reads in single-end mode.

The same track above shows in paired mode.

Show/Hide Read Names
Read names are available only when the variant field is specified. There is a checkbox that displays read names on the left side of the main BAM track as shown below. The read names are only displayed when the main BAM track has base-pair level resolution and is in nucleotide view (see section on vertical zoom in case of high-depth sequencing data).

Displaying PCR and Optical Duplicated Reads

The checkbox in the configuration panel can be toggled to switch on/off the display of PCR and optical duplicates. In the above figure, a total of 29 reads are shown when PCR/optical duplicates are displayed (Figure a) whereas a total of 19 reads are displayed supporting the alternative allele when PCR/optical duplicates are not displayed (default, Figure b).
Strictness
This option is available when the BAM track is performing on-the-fly genotyping against a variant. The user can toggle between Lenient and Strict (default) mode as shown in the ppBAM configuration panel.
Read Information Panel
For displaying the various features of individual reads, on clicking a particular read (in nucleotide view) a new panel opens displaying the information about the selected read (as shown below).
In this panel (as shown above), the top row shows the reference sequence that is aligned to the read. The second row shows the nucleotide sequence of the read. The colors of the nucleotides of the read are based on the CIGAR sequence of the read and follow the color codes as described in the section color coding of reads. In the third row, three clickable buttons are available which have the following functions as described below. The fourth row contains the start, stop, read length, template length, CIGAR sequence, flag and name of read.
When the read sequence is not available, but the CIGAR sequence is available then the read panel displays the message "Nucleotide sequence not available for this read".

Copy Read Sequence
The Copy Read Sequence feature copies the nucleotide sequence of the read being displayed to the computer clipboard so that it can be pasted outside of ppBAM.
Show Gene Models
On clicking the Show Gene Models button, the gene model (as shown below) is displayed.

Read Details
The fourth row contains details about the read present in the BAM file
-
CHR -Chromosome ID of the read.
-
START -Contains the start position of the read.
-
STOP -Contains the stop position of the read.
-
This Read -Contains length of the read.
-
TEMPLATE -Contains length of the template of which the current read is part of.
-
CIGAR -Contains CIGAR sequence of the read.
-
FLAG -Contains the flag number (from BAM file) of the read.
-
NAME -Contains the name of the read.
Color Coding of Reads
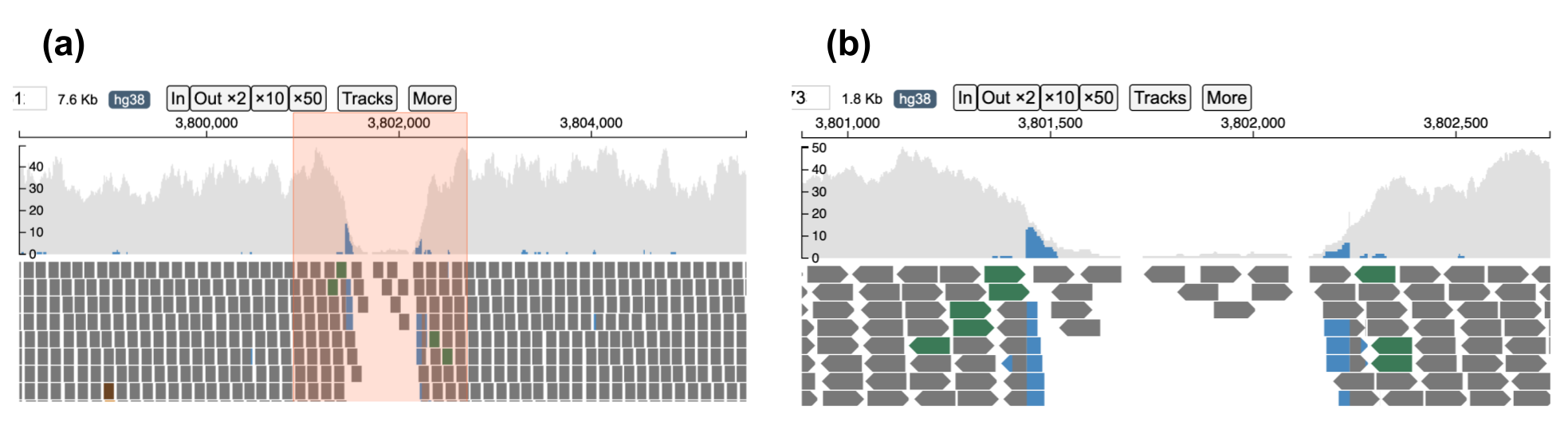
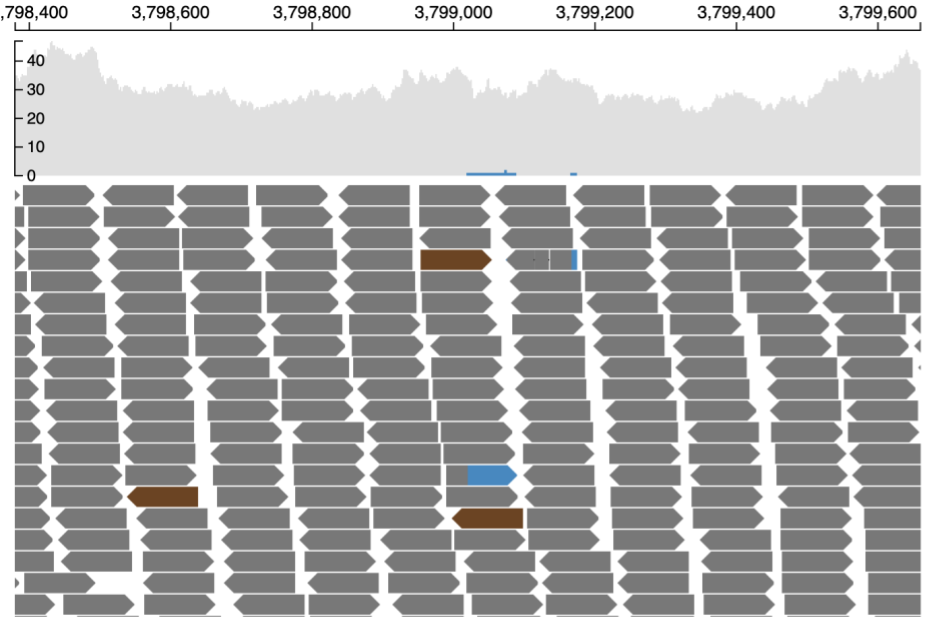
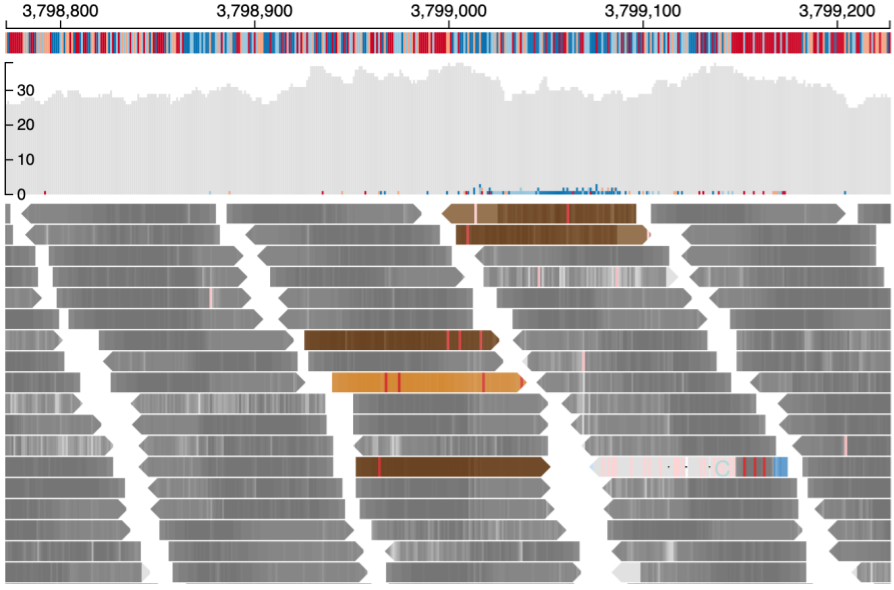
Reads near the vicinity of the deletion have various colors (gray, green, brown and blue) based on their features as explained below. In the paired-end view (a) an overview of the deletion is shown. In Base-pair resolution mode (b) nucleotides of each of the reads which are softclipped reads starting near position chr16: 3,801,439 are shown.
(a) Paired-end view

(b) Base-pair resolution mode showing nucleotides of each of the reads

Color codes in the background (as shown above) of the read describe the quality of the alignment of the read and its mate (in case of paired-end sequencing). These colors are assigned both on the basis of the CIGAR sequence (if it contains a softclip) and the flag value of both the read and its mate.
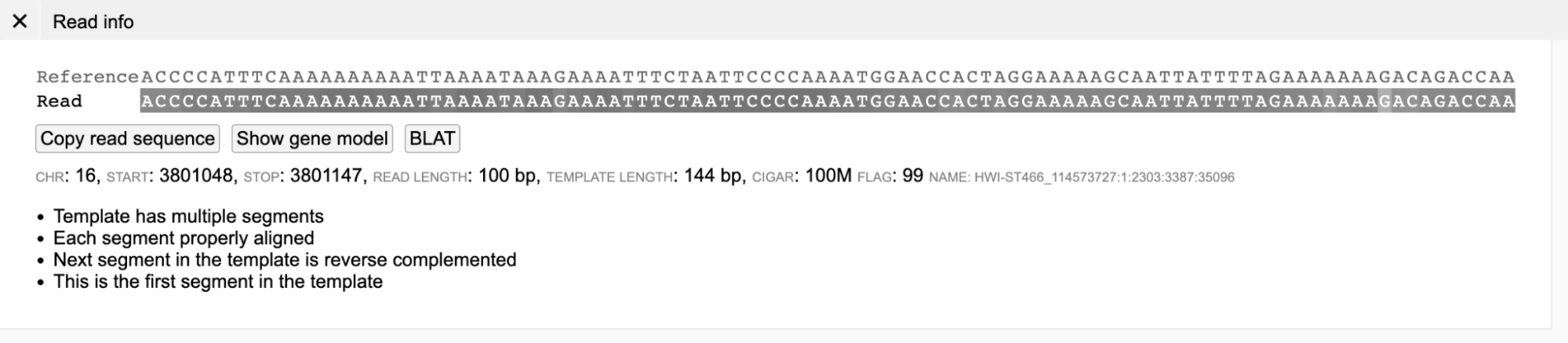
Gray
Presence of gray background nucleotides in a read suggests that both the read (at least part of it) and its mate are properly aligned and the insert size is within expected range (as shown below).
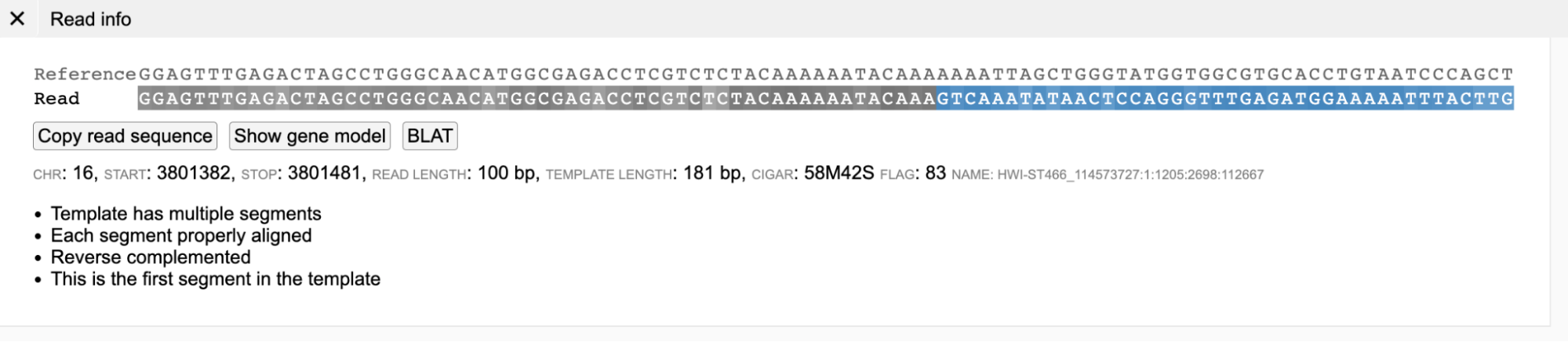
Blue
Presence of blue-background nucleotides in a read indicates that part of the read is soft clipped (as shown below). The last 42 nucleotides in the read below are softclipped based on CIGAR sequence (58M42S).
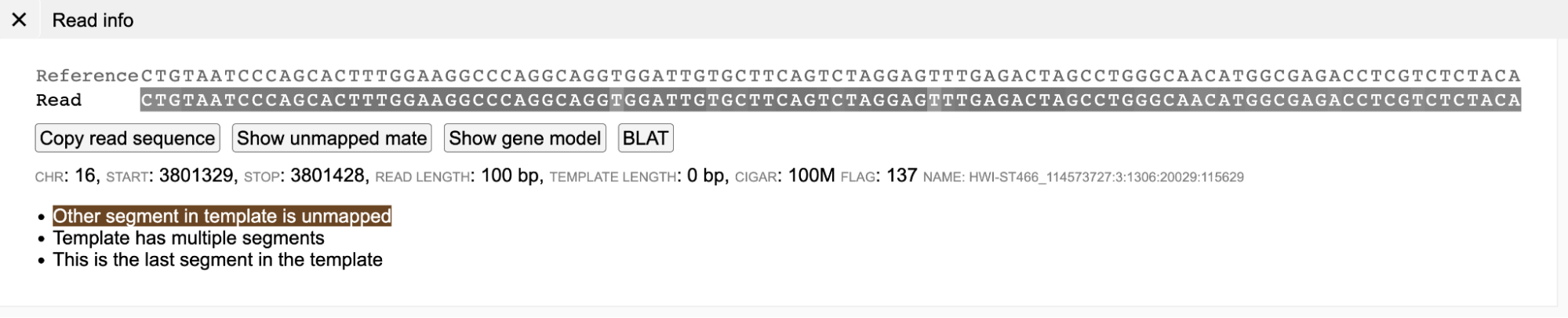
Brown
A brown colored background (in the main read alignment plot) indicates that the mate of the read is unmapped. On clicking a read with unmapped mate in the read information panel, the current read sequence is displayed along with a button "Show unmapped mate".
On clicking the button "Show unmapped mate", the sequence of the unmapped mate is also displayed.

Green
A green background (shown below) indicates that the template has the wrong insert size. As shown in the Read Info figure below, the reads labeled green have a higher insert size than normal (gray) reads because of the structural deletion. In paired-end view, generally such read-pairs have a much longer gray-dashed line than properly aligned (Gray) read-pairs.
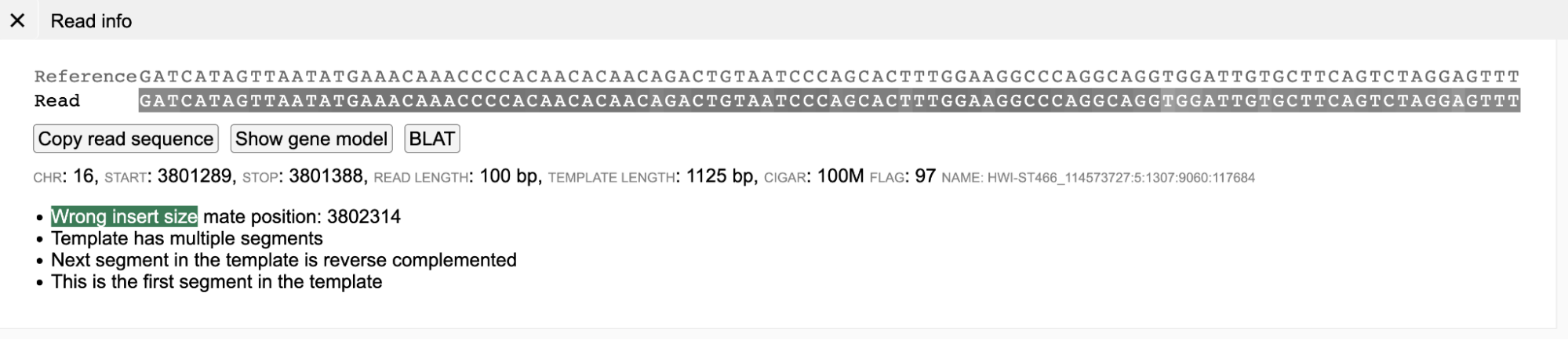
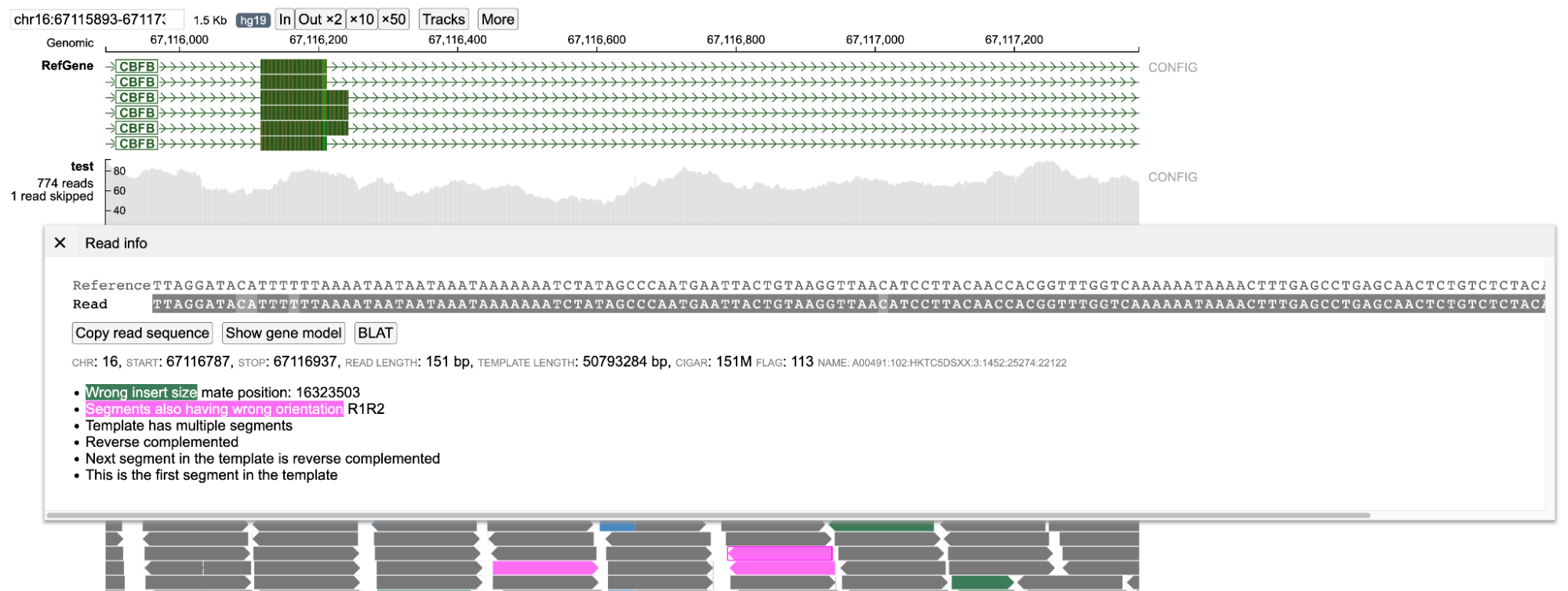
Pink
A pink color background indicates that the orientation of the read and its mate is not correct. Several orientations are taken into consideration. The figure below displays an example of an inversion caused due to CBFB-MYH11 gene fusion found in Acute Myeloid Leukemia patients. Here the read and its mate are oriented in the reverse direction (R1R2). * F1F2 - When both read and its mate are pointing in the forward direction (-> ->). * R1R2 - When both read and its mate are pointing in the reverse direction (<- <-). * F1R2 - When both read and its mate are pointing in forward and reverse direction but are pointing in opposite directions (<- ->).
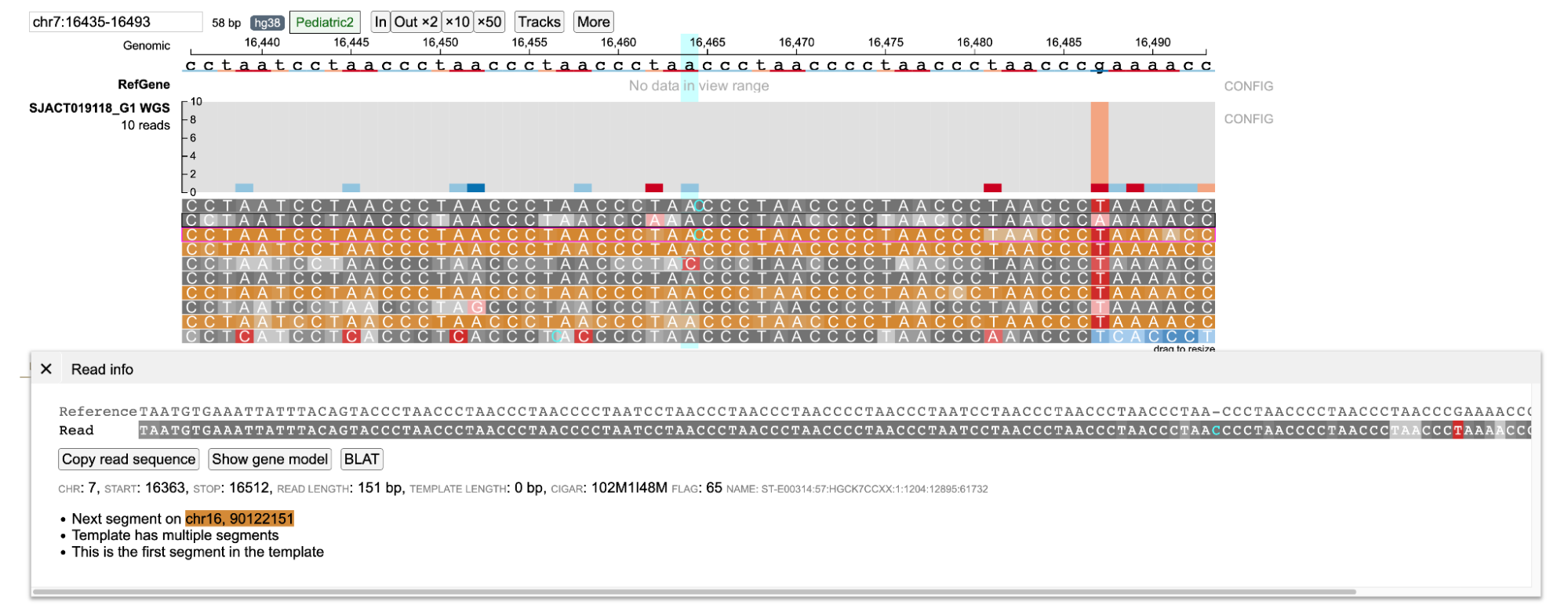
Orange
Orange background color indicates the read and its mate are mapped in different chromosomes. The displayed read is mapped in chr7:16363-16512 whereas its mate is mapped in chr16.
Variant Mode
Variant Mode provides an intuitive view of a variant specified by the user inside ppBAM. On specifying the chromosome, position, reference and alternative allele; the reads covering the variant region are displayed and classified into groups supporting the reference allele, alternative allele, none (neither reference nor alternative allele) and ambiguous groups. This mode is invoked when the "variant" field is specified containing the chromosome, position, reference and alternative allele of the variant.
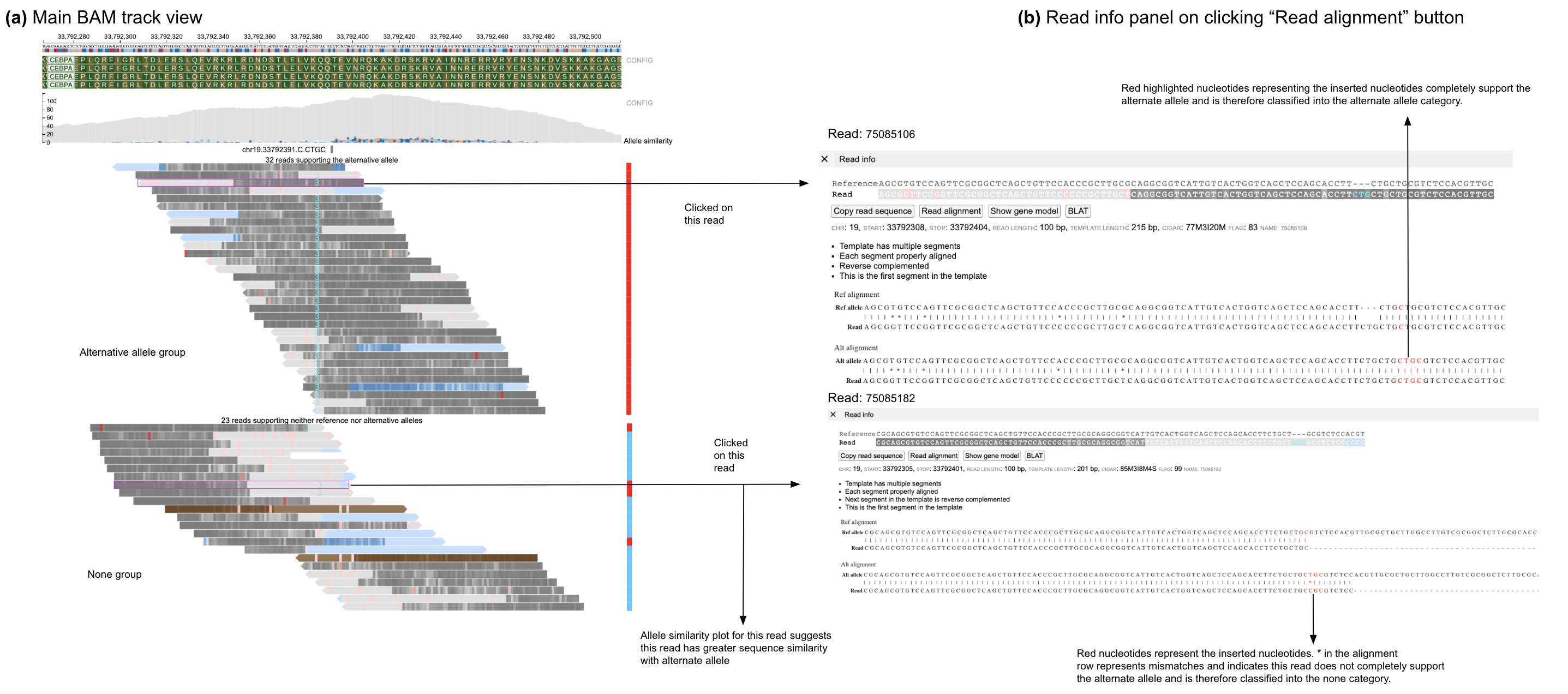
Alternative, Reference, None and Ambiguous Read Classification Groups
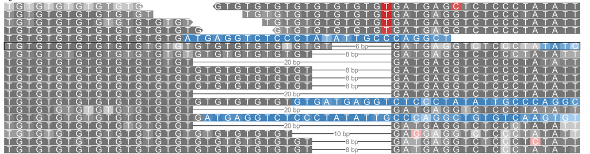
For a given variant (SNV or indel), reads mapping to the variant region are classified into Reference, Alternative (possibly multiple alternative alleles when multi-allele variants are queried), None (neither reference nor alternative allele) and Ambiguous (unclassified reads) groups by using the Smith-Waterman alignment (as shown in figure below).
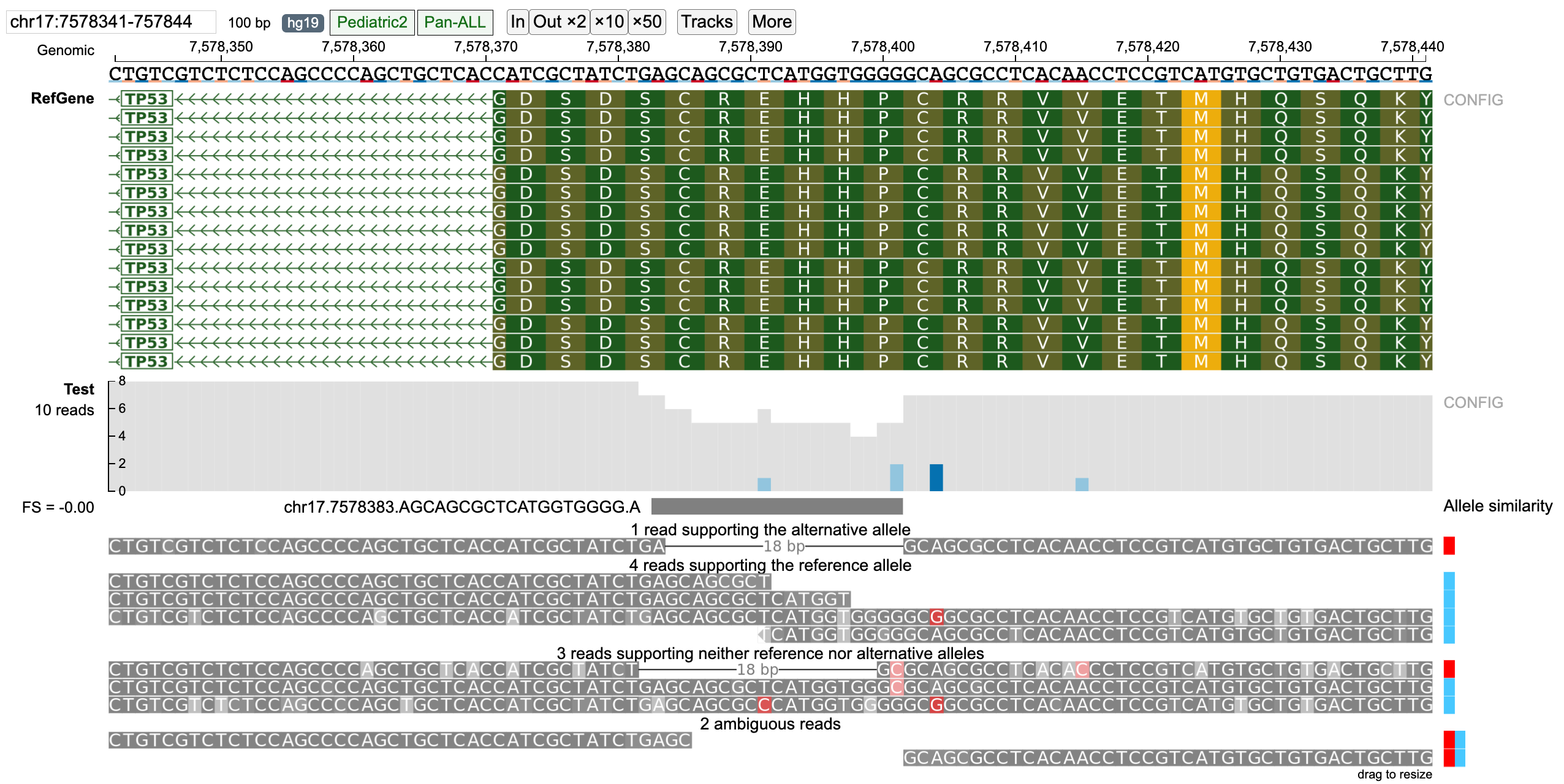
Reads are classified into supporting Alternative/Reference allele on the basis of "Allele similarity" which consists of selecting the allele with which the read has the highest identity ratio (number of matched nucleotides/total alignment length) (highest identity ratio highlighted in bold). Reads which do not completely match with neither reference nor alternative alleles are classified into none group (when strictness level = 'Strict') and those that have equal allele similarity to both reference and alternative allele (or multiple alternative alleles in case of multi-allele variants) are classified into the ambiguous group. The barplot on the right displays the "Allele similarity" for each read. This barplot is especially helpful in analyzing reads classified into the none group by indicating the alternative/reference allele with which it has maximum sequence similarity.
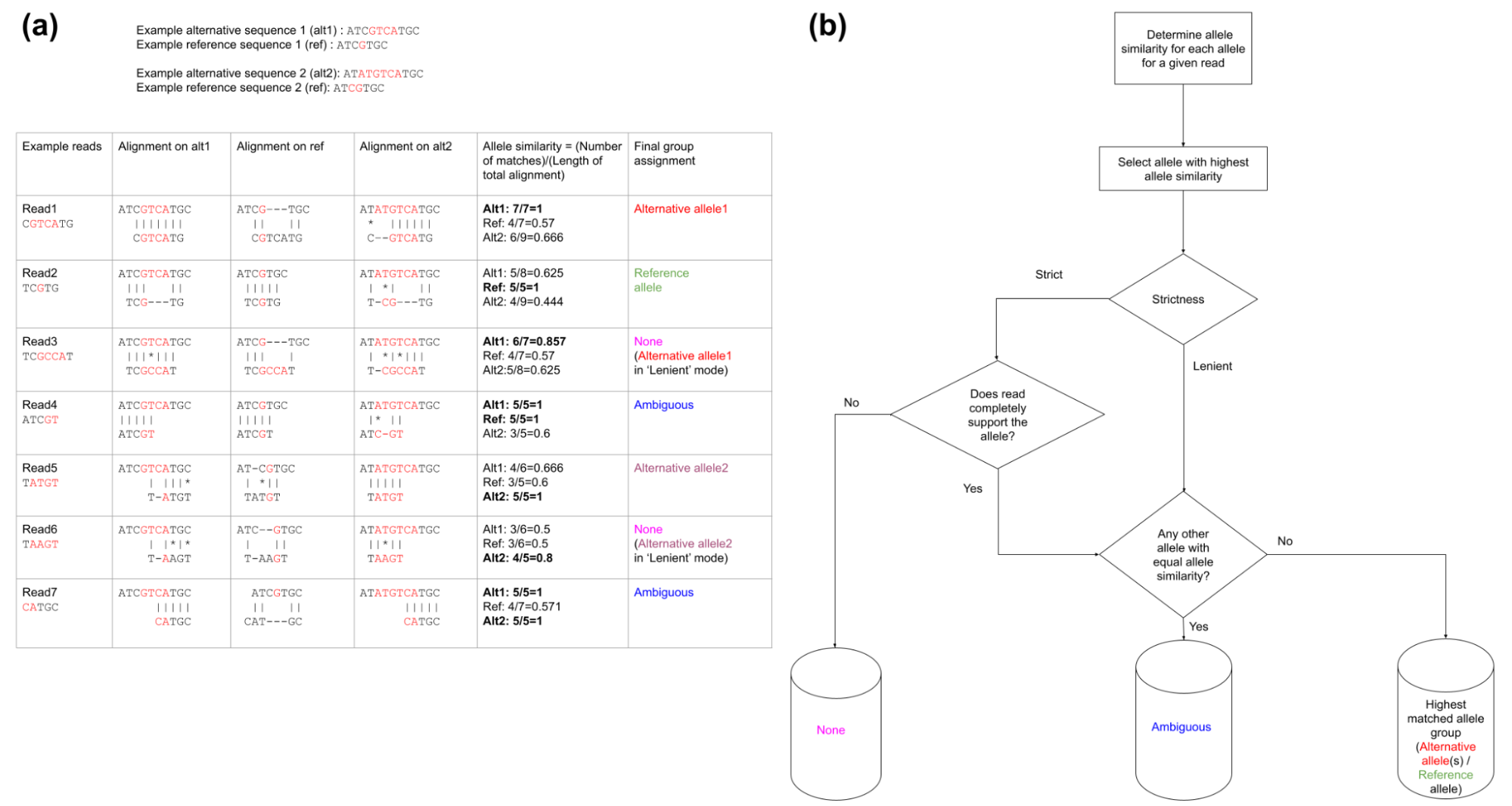
Above figure describes the methodology for classification of reads into Reference, Alternative (possibly multiple alternative alleles), None (neither reference nor alternative allele) and Ambiguous groups. Classification of seven reads are described for a multi-allele variant (G/GTCA) and (CG/ATGTCA). (a) Sequence alignment of various reads to alternative and reference alleles (red colored nucleotides represent alternative and reference allele nucleotides): Read1 and Read2 completely support the alternative allele-1 and reference allele respectively. Read3 has the highest sequence similarity to the alternative allele-1 but has a mismatch and is therefore classified into the none group when strictness = 'Strict' and classified into alternative allele-1 when strictness = 'Lenient'. Read4 has equal similarity to both reference and alternative allele-1 and is classified into the ambiguous group. Read5 has the highest allele similarity and a complete match to alternative allele-2. Read6 has the highest sequence similarity to the alternative allele-2 but has a mismatch and is therefore classified into the none group when strictness = 'Strict' and classified into alternative allele-2 when strictness = 'Lenient'. Read7 has equal allele similarity to alternative allele-1 and alternative allele-2 and is classified into the ambiguous group (b) A generalized flow chart for classifying reads into (possibly) multiple alternative/reference alleles using "Allele similarity" values and the "Strictness" setting. The "None" group contains reads which do not support neither reference nor alternative allele(s) will be created only when the "Strictness" setting is set to "Strict" (default). Ambiguous group consists of reads that have equal allele similarity to two (or more) alleles.
Ambiguous Reads
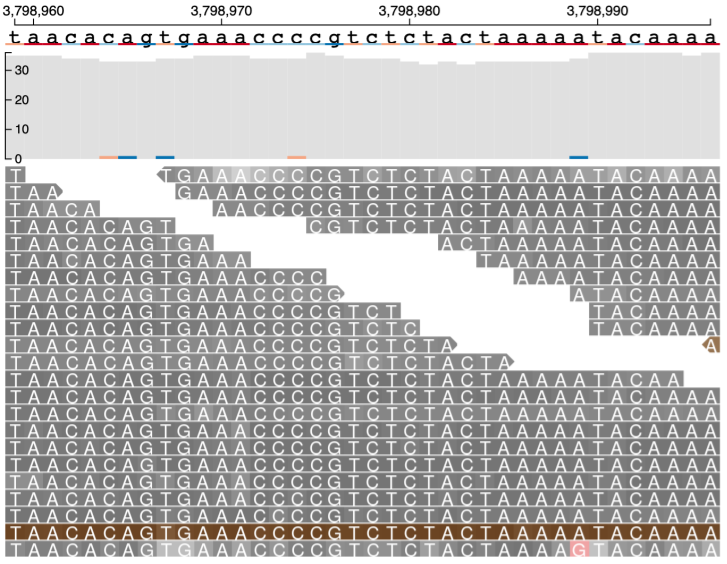
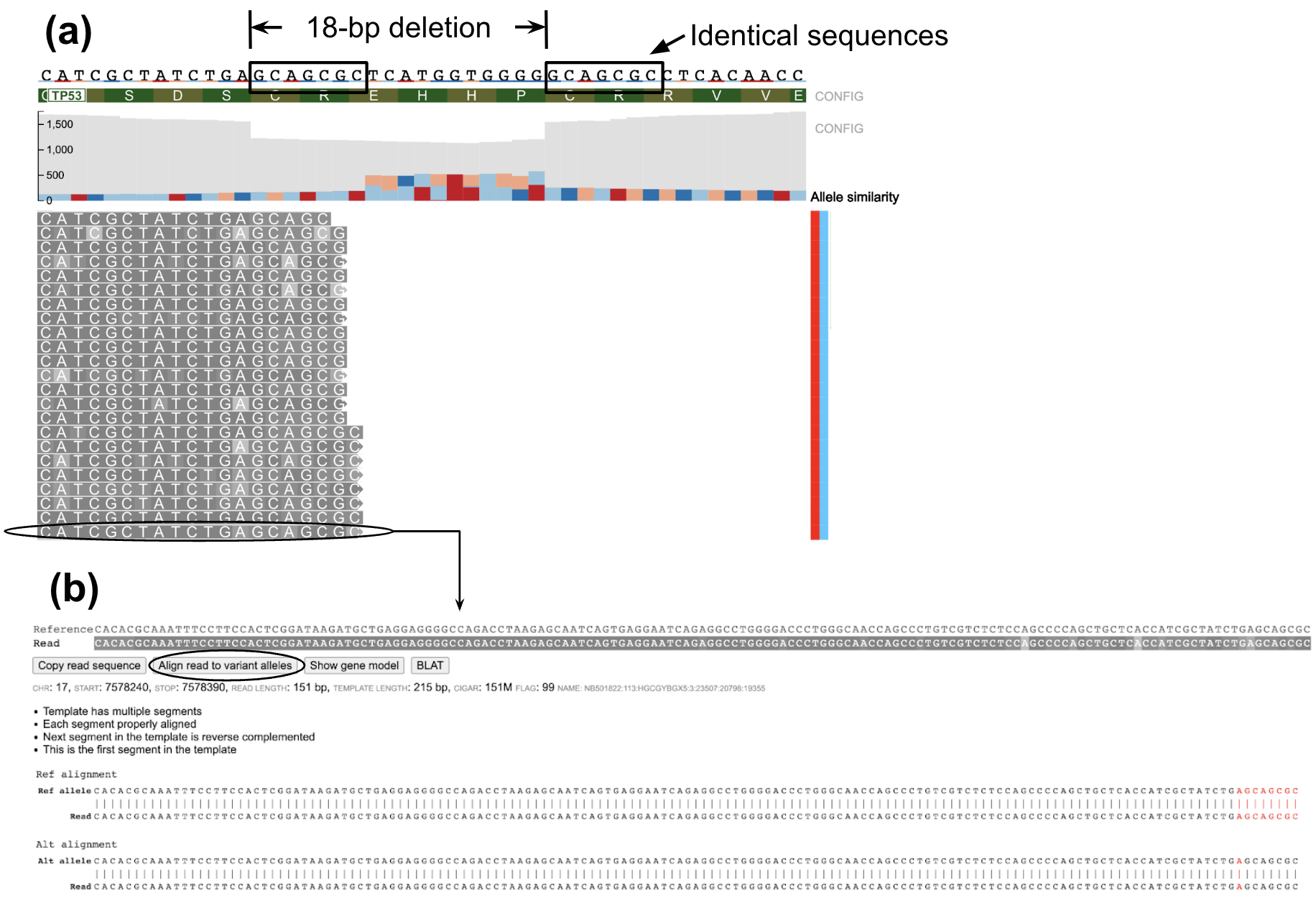
In certain indels such as example below, certain reads in the variant region can have equal similarity towards both the reference and alternative allele. A large number of ambiguous reads are on the left-side of the indel (Figure a below) because the deletion starts with the sequence GCAGCGC which is also found in the right flanking sequence resulting in equal similarity to both reference and alternative alleles for any read ending within this part of the indel region. On viewing the read alignment for the ambiguous read (Figure b below) through the read information panel, it is observed that the read has equal similarity to both reference and alternative alleles. Nucleotides highlighted in red indicate those which are part of reference/alternative allele.
Fisher-strand Analysis to Check for Strand Bias in Variants
Fisher-strand (FS) analysis on ratio of forward/reverse strand reads in the alternative and reference groups can help in detecting possible strand bias that may be present in the variant of interest. The FS score is the Phred-scaled p-value from the Fisher test of the contingency table consisting of forward/reverse strand reads from both the alternative and reference alleles (as shown in figure below). To increase performance for high-depth sequencing examples, when the sequencing depth is greater than 300 the chi-square test is used (if equal or lower than this number, the Fisher's exact test is used). If FS score is greater than 60, the FS score is highlighted in red (as shown below) indicating that there may be a possible strand bias in the variant.
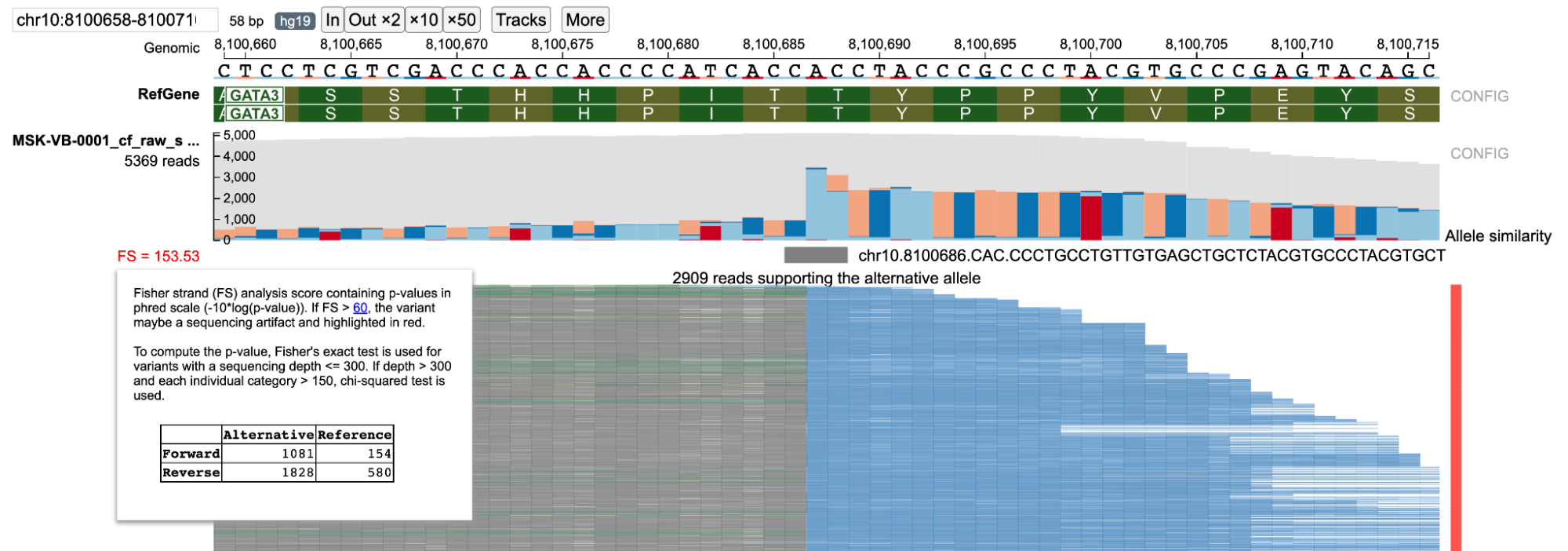
In the figure above, a complex indel is shown containing Fisher strand bias. The FS score is highlighted in red indicating this particular variant may contain strand bias.
Strictness in On-the-fly Genotyping
A user can also optionally change the strictness of the algorithm to Lenient/Strict (default) from the ppBAM configuration panel. For strictness level = 'Lenient', reads are classified based on higher sequence similarity to reference/alternative allele. In case of strictness level = 'Strict', the exact sequence of the reference/alternative allele in the read is compared against the allele sequence given by the user. Reads that do not match either allele are classified into the none group (when strictness level = 'Strict'), the allele similarity plot shows the color of the allele to which the read has maximum sequence similarity.

The lenient strictness level can be helpful, when the user wants a lenient estimate of the number of reads supporting the particular indel of interest or when the user is confident that only one alternative allele exists. This can also be helpful when there are reads with low base-pair quality calls near the variant region. In contrast when the strictness level is set to 'Strict', a more conservative estimate of the read support is provided for each allele and may indicate the presence of a wrong variant call (if present) or may indicate presence of multiple alternative alleles.
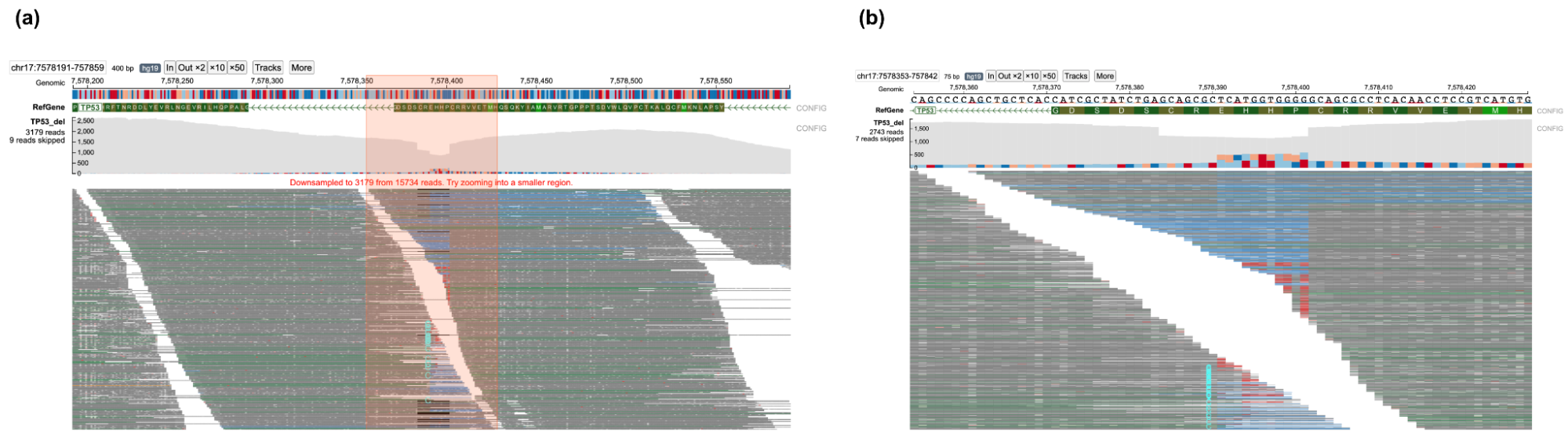
In case of the TP53 deletion example, select reads with wrong base pair calls are shown. For strictness level = 'Lenient', there are two reads that support the alternative allele. However, read NB501822:110:HLWKJBGX5:4:22410:10829:14705 has a wrong base pair call at position 7578401.

When the strictness level is changed to 'Strict', this read is classified into the none group.

Similarly, reads NB501822:113:HGCGYBGX5:3:23612:16815:9517 (wrong base-pair call at 7578401) and NB501822:113:HGCGYBGX5:2:22101:3565:18789 (wrong base-pair call at 7578391) are classified in the reference allele group when strictness level = 'Lenient' but are classified into the none group when strictness level is set to 'Strict'.
The 'Lenient' strictness level is generally only helpful in cases where only one alternative allele is present as it assumes that the given reference and alternative allele are the only possible cases. For multi-allelic variants or when a region has a large number of reads with low Phred base-pair quality nucleotides, the 'Strict' (default) level should be used.
Display of Read Alignment with Respect to Reference and Alternative Allele
In case of reads that are classified into the none group (when strictness level = 'Strict') it can be difficult to understand the classification into that group. For example, in case of insertions with the wrong nucleotide (with respect to the predicted alternative allele) the sequence of the inserted nucleotides is not shown in the main BAM track and can only be viewed through the read information panel.
Display of read alignment of the read with respect to both the reference and alternative allele helps provide an intuitive view for describing classification of a read into its respective group.