Exploration
The Exploration Page allows users to explore data in the GDC using advanced filters/facets, which includes those on a gene and mutation level. Users choose filters on specific Cases, Genes, and/or Mutations on the left of this page and then can visualize these results on the right. The Gene/Mutation data for these visualizations comes from the Open-Access MAF files on the GDC Data Portal. There is also a Clinical tab with filters that apply specifically to clinical data.
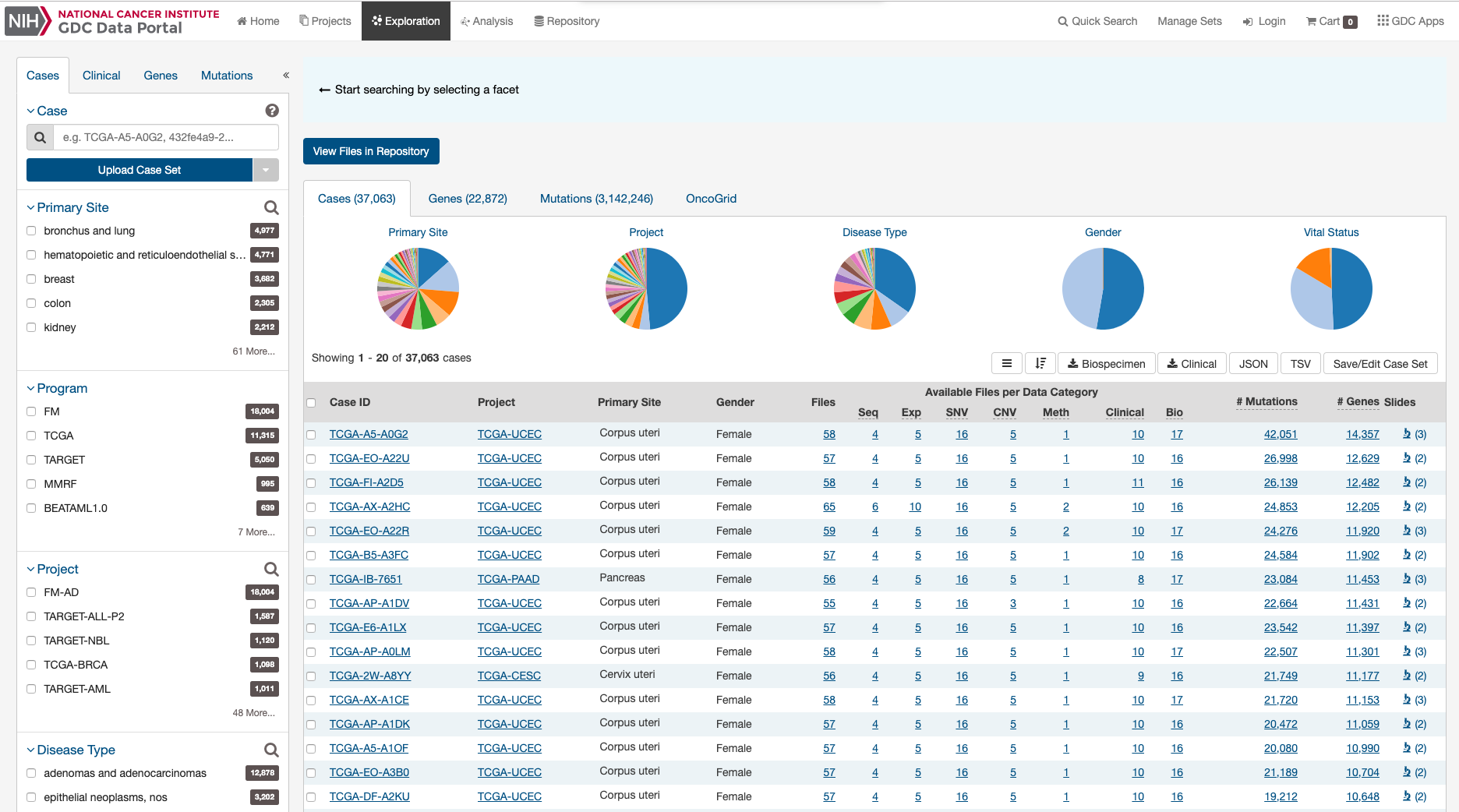
Filters / Facets
On the left of this page, users can create advanced filters to narrow down results to create synthetic cohorts.
Case Filters
The first tab of filters is for cases in the GDC.
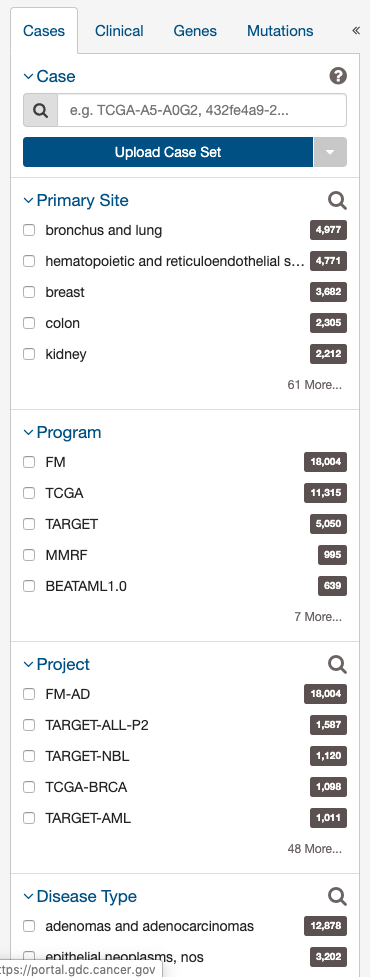
These criteria limit the results only to specific cases within the GDC. The default filters available are:
- Case: Specify individual cases using submitter ID (barcode), UUID, or list of Cases ('Case Set').
- Primary Site: Anatomical site of the cancer under investigation or review.
- Program: A cancer research program, typically consisting of multiple focused projects.
- Project: A cancer research project, typically part of a larger cancer research program.
- Disease Type: Type of cancer studied.
- Experimental Strategy: Experimental strategy used for molecular characterization of the cancer.
- Sample Type: Describes the source of a biospecimen used for a laboratory test.
- Available Variation Data: Indicates the types of genomic variation data that a case has been tested for.
Clinical Filters
The second tab of filters is used to specifically explore clinical data for cases in the GDC.
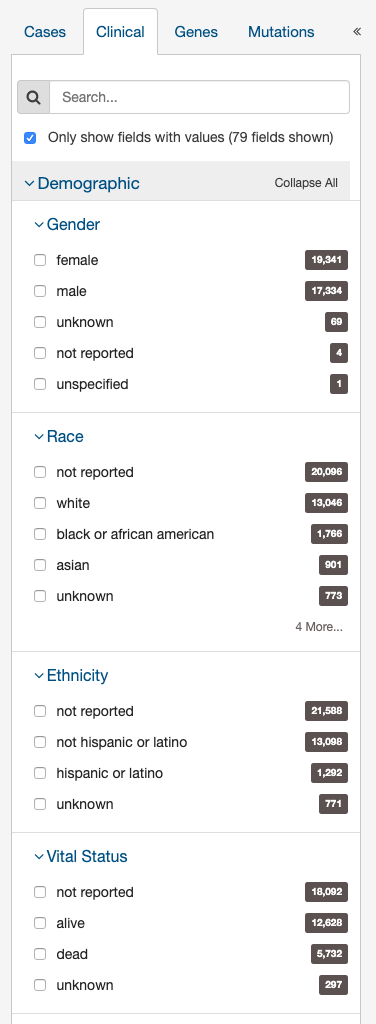
Users can filter by specific clinical variables, grouped into these categories:
- Demographic: Data for the characterization of the patient by means of segmenting the population (e.g. characterization by age, sex, race, etc.).
- Diagnoses: Data from the investigation, analysis, and recognition of the presence and nature of disease, condition, or injury from expressed signs and symptoms; also, the scientific determination of any kind; the concise results of such an investigation.
- Treatments: Records of the administration and intention of therapeutic agents provided to a patient to alter the course of a pathologic process.
- Exposures: Clinically-relevant patient information not immediately resulting from genetic predispositions.
Gene Filters
The third tab of filters is for genes affected by mutations in the GDC.
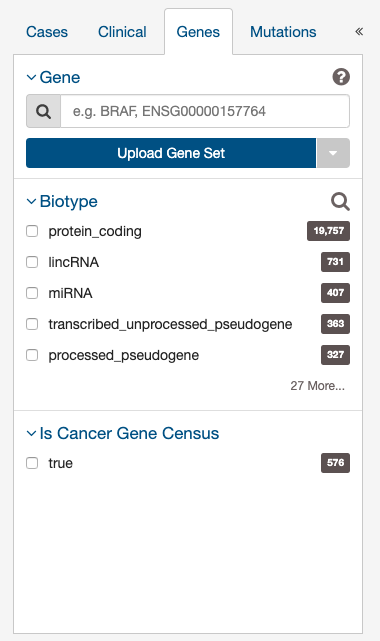
Users can filter by:
- Gene: Specify a Gene Symbol, ID, or list of Genes ('Gene Set').
- Biotype: Classification of the type of gene according to Ensembl. The biotypes can be grouped into protein coding, pseudogene, long noncoding and short noncoding. Examples of biotypes in each group are as follows:
- Protein coding: IGC gene, IGD gene, IG gene, IGJ gene, IGLV gene, IGM gene, IGV gene, IGZ gene, nonsense mediated decay, nontranslating CDS, non stop decay, polymorphic pseudogene, TRC gene, TRD gene, TRJ gene, TRV gene.
- Pseudogene: disrupted domain, IGC pseudogene, IGJ pseudogene, IG pseudogene, IGV pseudogene, processed pseudogene, transcribed processed pseudogene, transcribed unitary pseudogene, transcribed unprocessed pseudogene, translated processed pseudogene, translated unprocessed pseudogene, TRJ pseudogene, TRV pseudogene, unprocessed pseudogene.
- Long noncoding: 3 prime overlapping ncrna, ambiguous orf, antisense, antisense RNA, lincRNA, macro lincRNA, ncrna host, processed transcript, sense intronic, sense overlapping.
- Short noncoding: miRNA, miRNA pseudogene, miscRNA, miscRNA pseudogene, Mt rRNA, Mt tRNA, rRNA, scRNA, snlRNA, snoRNA, snRNA, tRNA, tRNA pseudogene, vaultRNA.
- Is Cancer Gene Census: Whether or not a gene is part of The Cancer Gene Census.
Mutation Filters
The final tab of filters is for specific mutations.
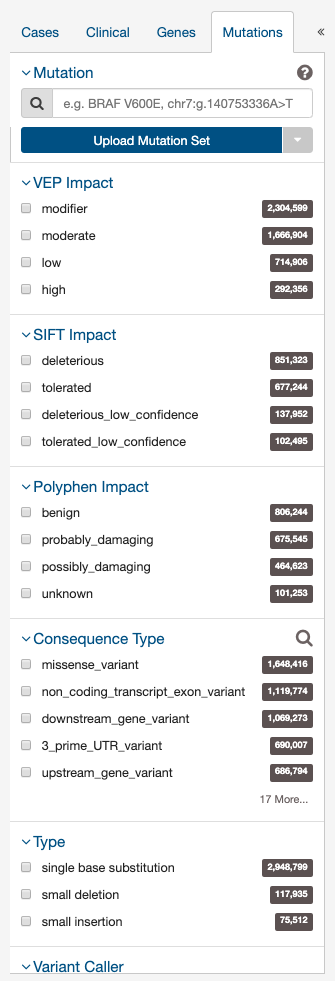
Users can filter by:
- Mutation: Unique ID for that mutation. Users can use the following:
- UUID - c7c0aeaa-29ed-5a30-a9b6-395ba4133c63
- DNA Change - chr12:g.121804752delC
- COSMIC ID - COSM202522
- List of any mutation UUIDs or DNA Change id's ('Mutation Set').
- Impact: A subjective classification of the severity of the variant consequence. These scores are determined using the three following tools:
- Ensembl VEP:
- HIGH (H): The variant is assumed to have high (disruptive) impact in the protein, probably causing protein truncation, loss of function or triggering nonsense mediated decay.
- MODERATE (M): A non-disruptive variant that might change protein effectiveness.
- LOW (L): Assumed to be mostly harmless or unlikely to change protein behavior.
- MODIFIER (MO): Usually non-coding variants or variants affecting non-coding genes, where predictions are difficult or there is no evidence of impact.
- PolyPhen:
- probably damaging (PR): It is with high confidence supposed to affect protein function or structure.
- possibly damaging (PO): It is supposed to affect protein function or structure.
- benign (BE): Most likely lacking any phenotypic effect.
- unknown (UN): When in some rare cases, the lack of data does not allow PolyPhen to make a prediction.
- SIFT:
- tolerated: Not likely to have a phenotypic effect.
- tolerated_low_confidence: More likely to have a phenotypic effect than 'tolerated'.
- deleterious: Likely to have a phenotypic effect.
- deleterious_low_confidence: Less likely to have a phenotypic effect than 'deleterious'.
- Ensembl VEP:
- Consequence Type: Consequence type of this variation; sequence ontology terms.
- Type: A general classification of the mutation.
- Variant Caller: The variant caller used to identify the mutation.
- COSMIC ID: This option will filter out only mutations with a COSMIC ID.
- dbSNP rs ID: This option will filter out only mutations with a SNP identifer maintained in dbSNP.
Results
As users add filters to the data on the Exploration Page, the Results section will automatically be updated. Results are divided into different tabs: Cases, Genes, Mutations, and OncoGrid.
To illustrate these tabs, Case, Gene, and Mutation filters have been chosen (Genes in the Cancer Gene Census, that have a missense variant for the TCGA-BRCA project) and a description of what each tab displays follows.
Cases
The Cases tab gives an overview of all the cases/patients who correspond to the filters chosen (Cohort).
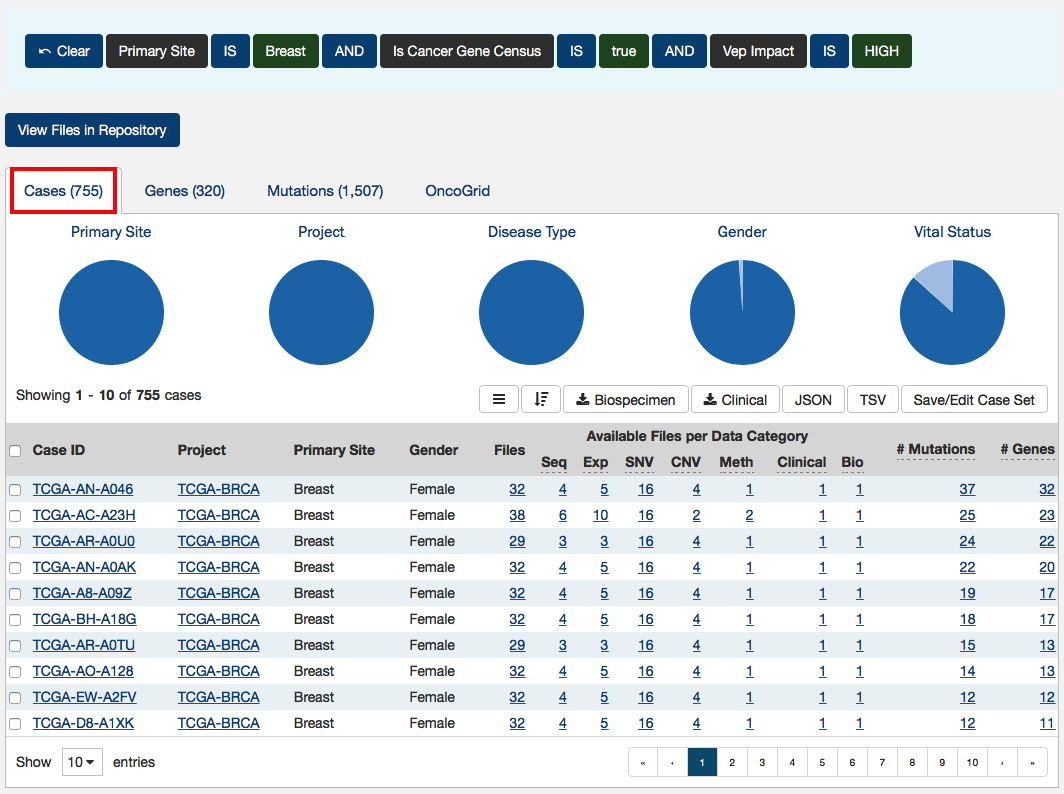
The top of this section contains a few pie graphs with categorical information regarding the Primary Site, Project, Disease Type, Gender, and Vital Status.
Below these pie charts is a tabular view of cases, which can be exported, sorted and saved using the buttons on the right and includes the following information:
- Case ID (Submitter ID): The Case ID / submitter ID of that case/patient (i.e. TCGA Barcode).
- Project: The study name for the project for which the case belongs.
- Primary Site: The primary site of the cancer/project.
- Gender: The gender of the case.
- Files: The total number of files available for that case.
- Available Files per Data Category: Seven columns displaying the number of files available in each of the seven data categories. These link to the files for the specific case.
- # Mutations: The number of SSMs (simple somatic mutations) detected in that case.
- # Genes: The number of genes affected by mutations in that case.
- Slides: The total number of slides available for that case. For more information about slide images.
Note: By default, the UUID is not displayed on summary page tables. You can display the UUID by clicking on the icon with 3 parallel lines and checking the UUID option.
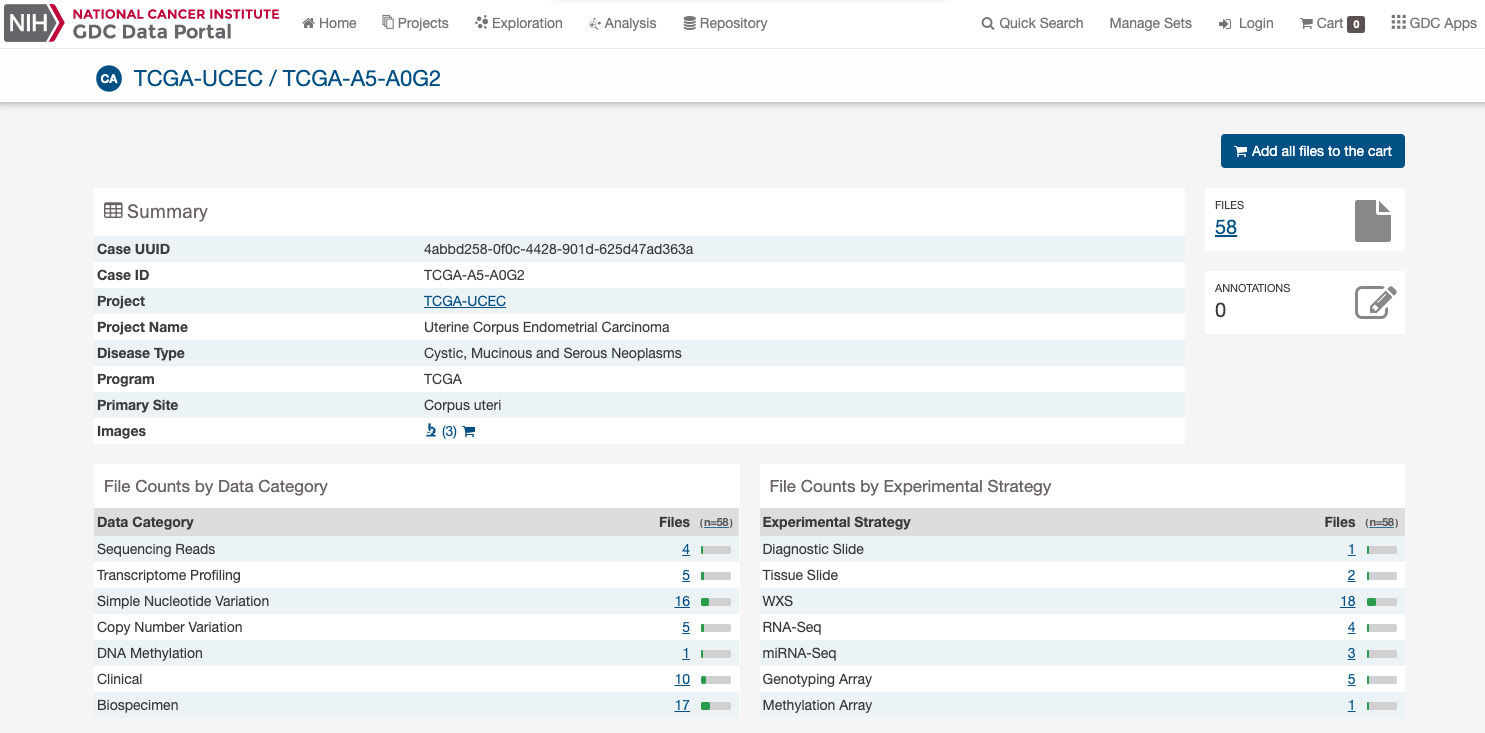
Case Summary Page
The Case Summary Page displays case details including the project and disease information, data files that are available for that case, and the experimental strategies employed. A button in the top-right corner of the page allows the user to add all files associated with the case to the file cart.
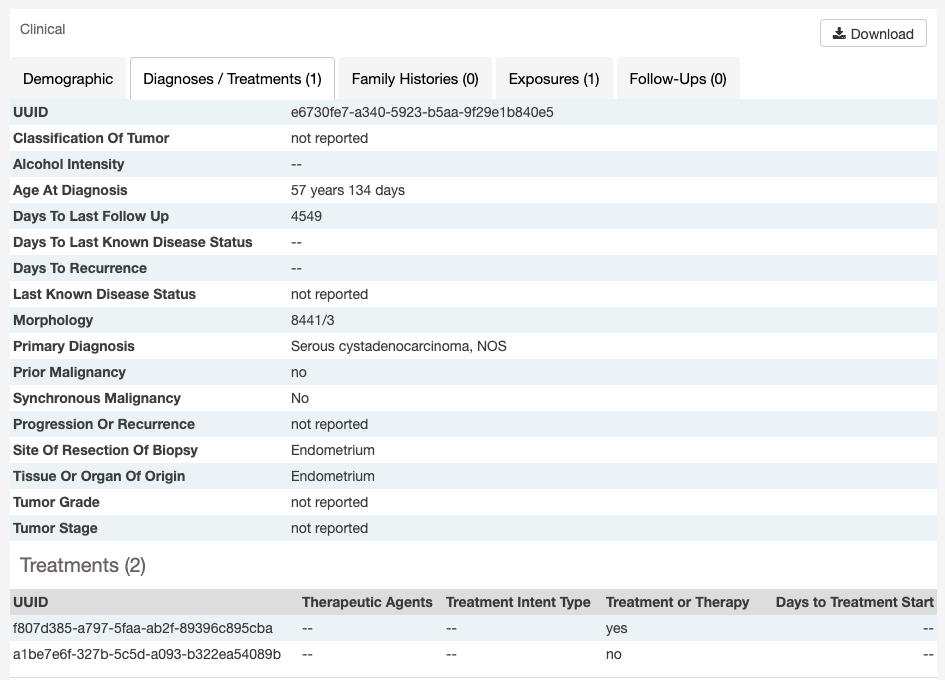
Clinical and Biospecimen Information
The page also provides clinical and biospecimen information about that case. Links to export clinical and biospecimen information in JSON format are provided.
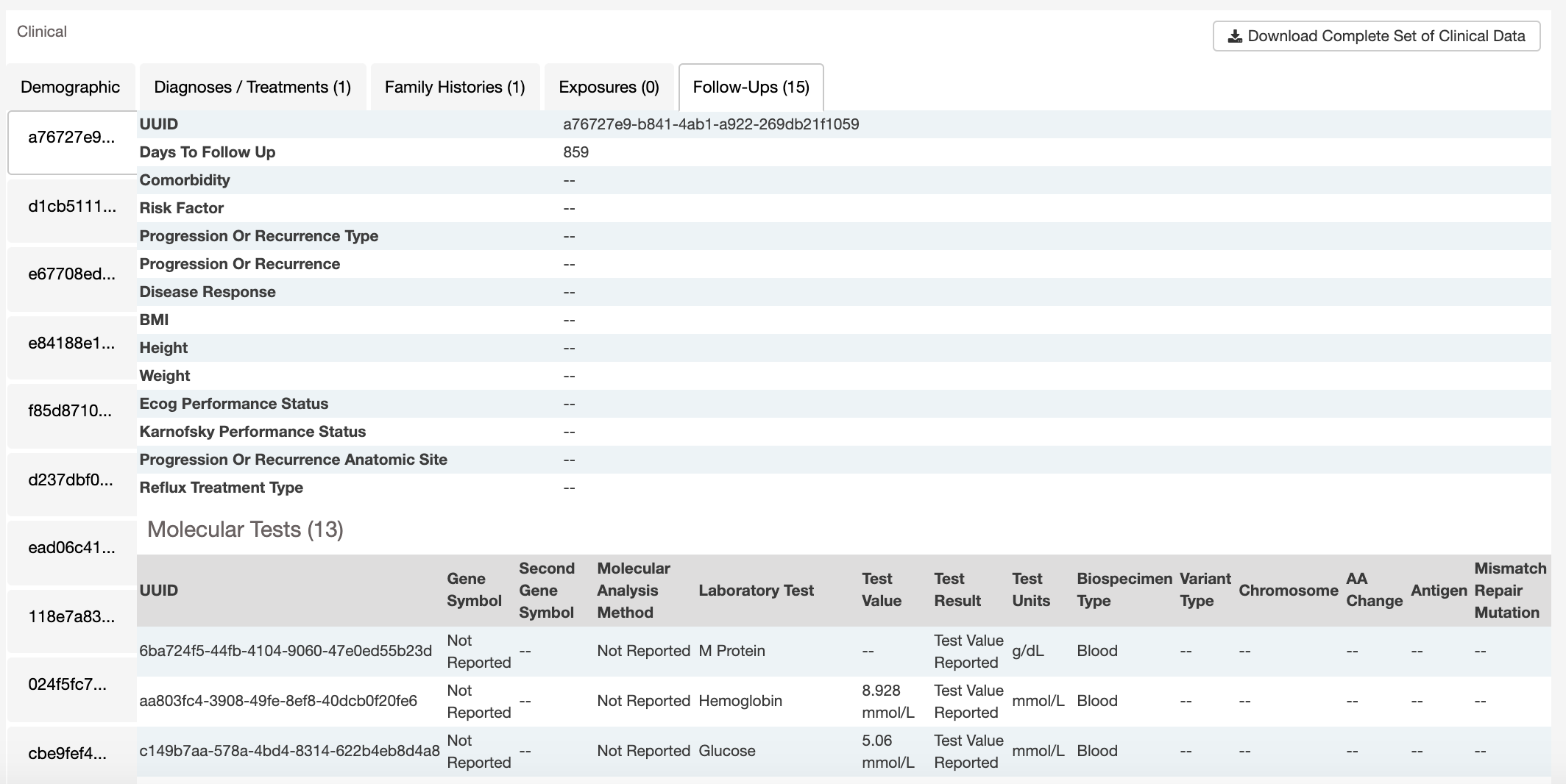
Some clinical records can support multiple records of the same type (Diagnoses, Family Histories, Exposures, Follow-Ups, Molecular Tests). If only one record exists, the UUID of the record is provided at the top of the corresponding tab.
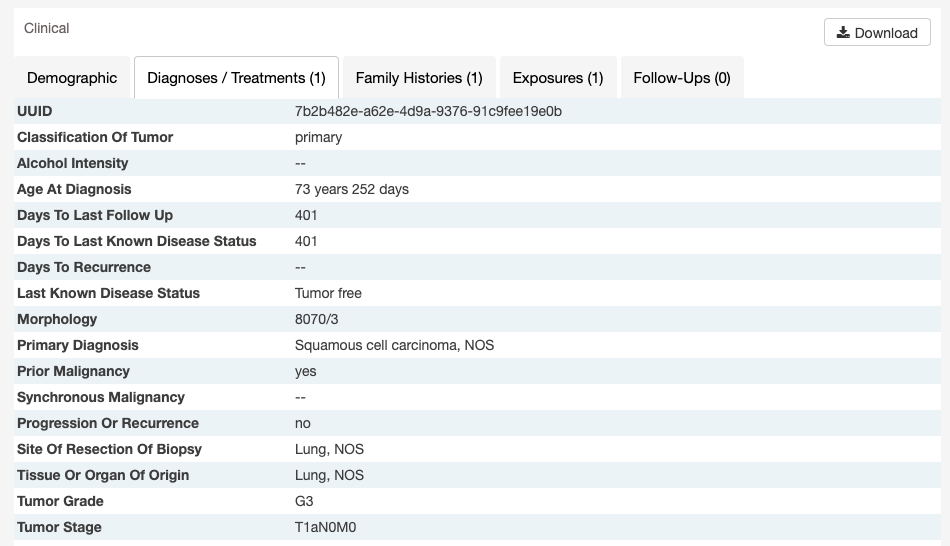
If there are multiple records, they are listed as horizontal tabs.
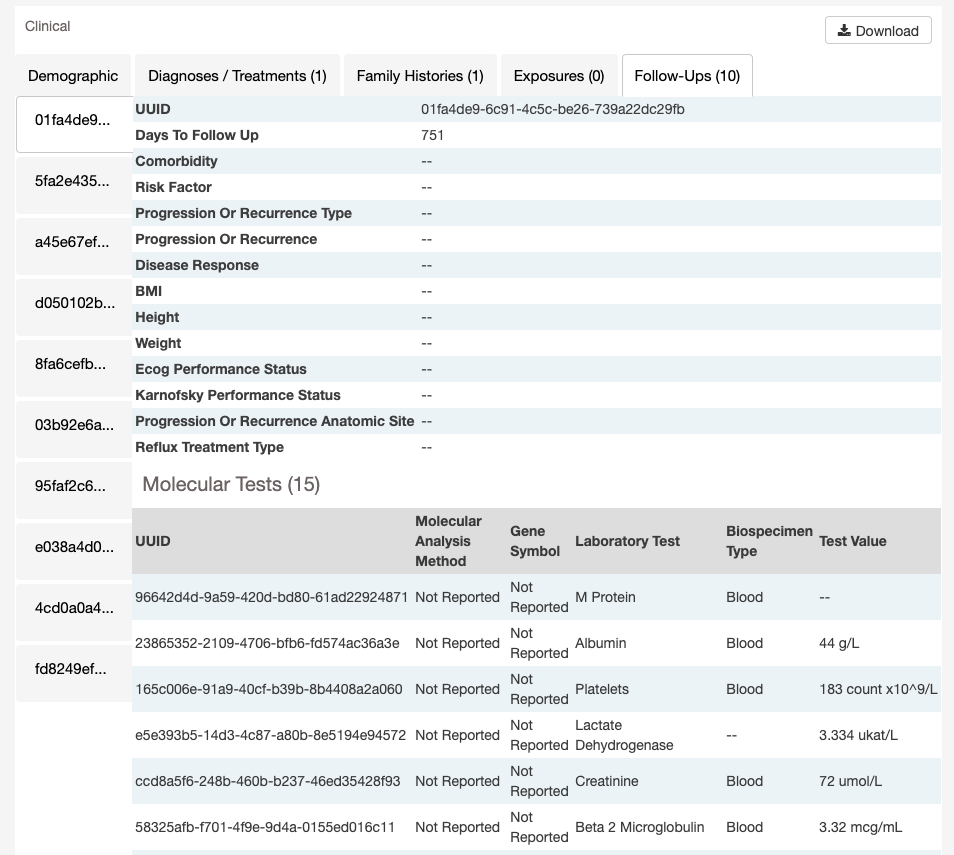
Some record types are further nested under another. For example, a Diagnosis record may have multiple associated Treatment records. Or a Follow-Up record may have multiple associated Molecular Test Records. The associated sub-records are listed in a table on the tab.
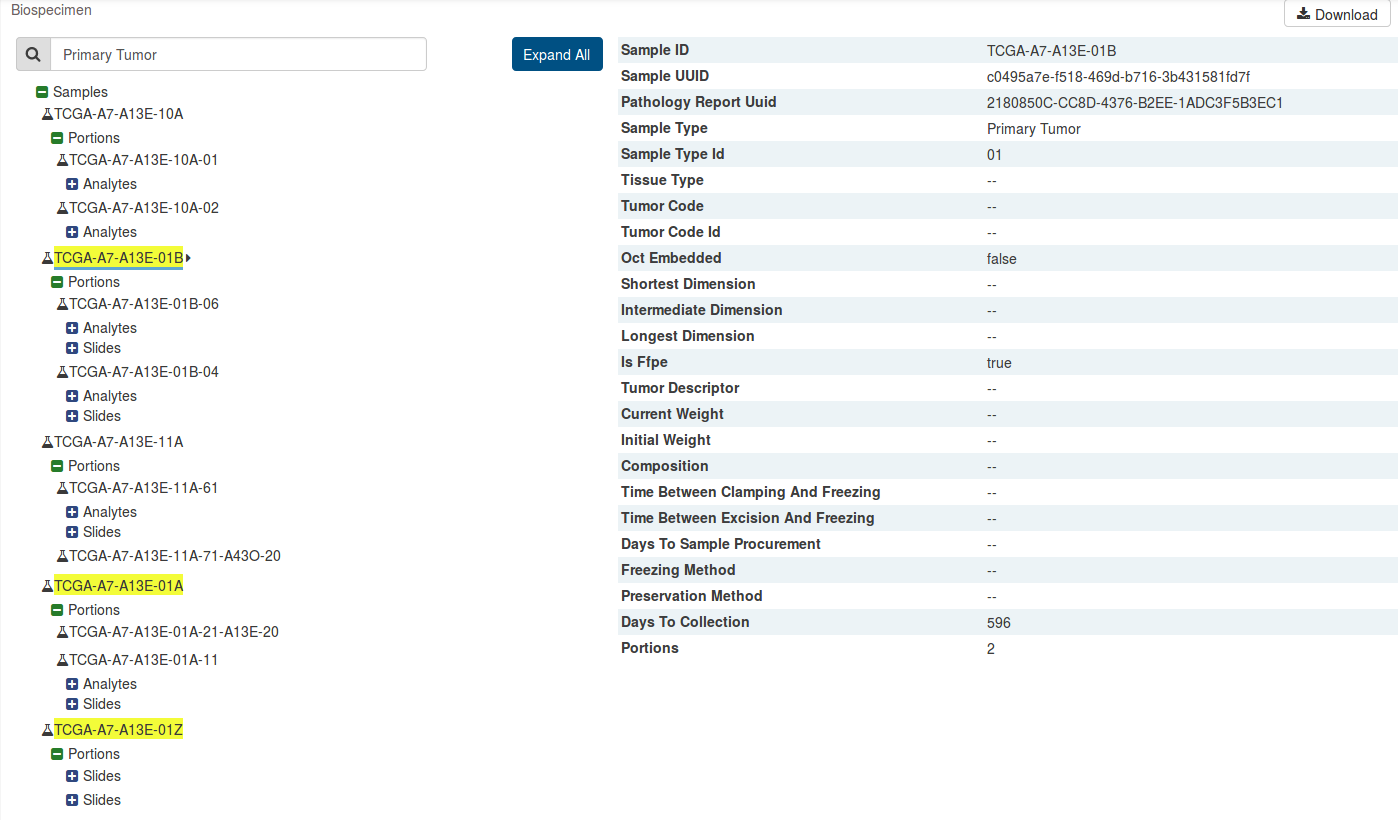
Biospecimen Search
A search filter just below the biospecimen section can be used to find and filter biospecimen data. The wildcard search will highlight entities in the tree that match the characters typed. This will search both the case submitter ID, as well as the additional metadata for each entity. For example, searching 'Primary Tumor' will highlight samples that match that type.
Most Frequent Somatic Mutations for a Case
The Case Entity Page also lists the mutations found in that particular case.
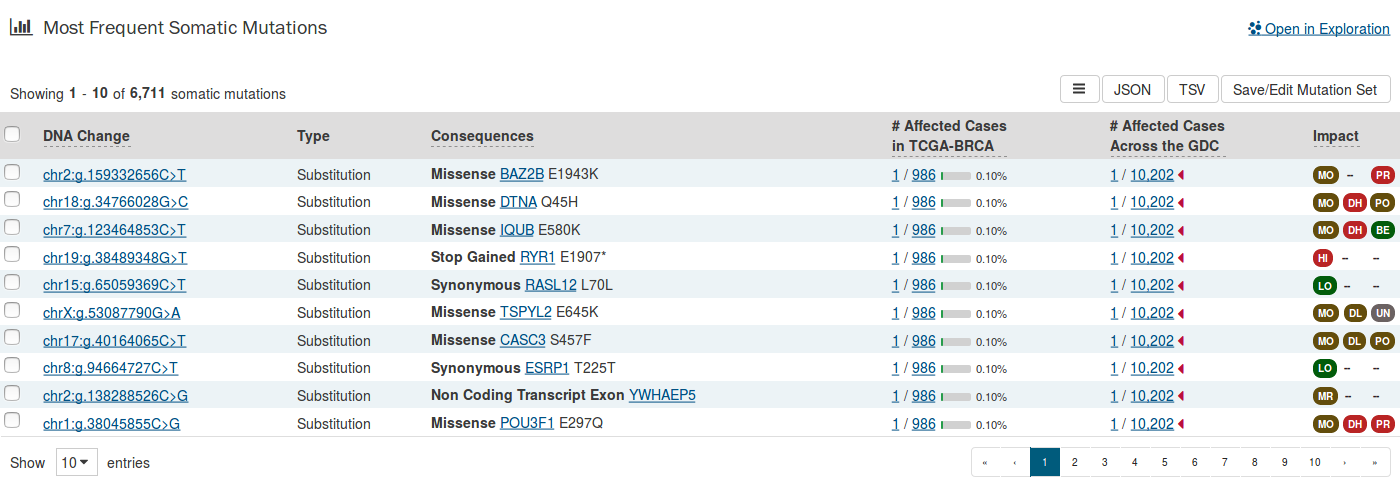
For more information, please go to the Most Frequent Somatic Mutation section.
Genes
The Genes tab will give an overview of all the genes that match the criteria of the filters (Cohort).
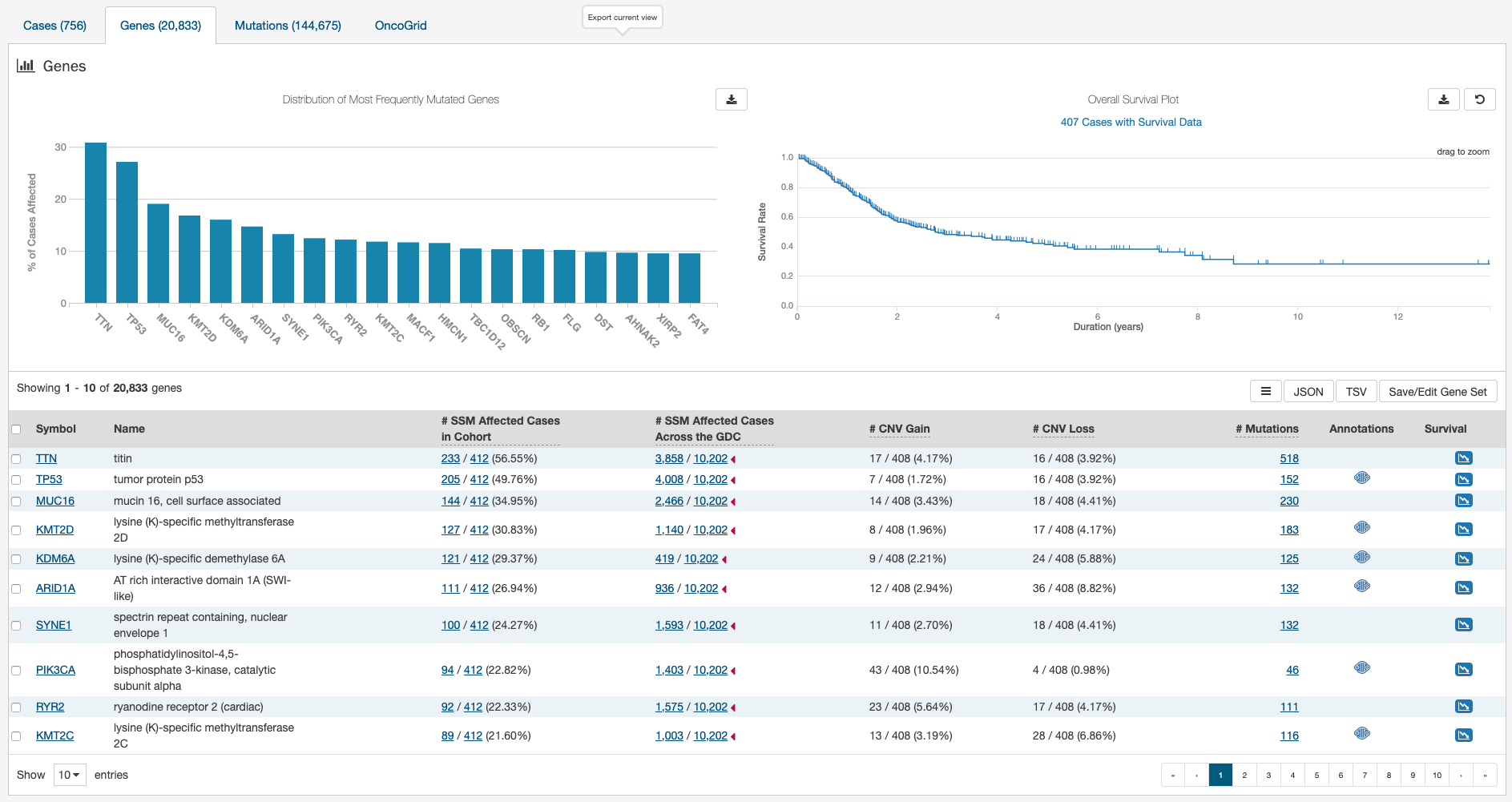
The top of this tab contains a bar graph of the most frequently mutated genes. Hovering over each bar in the plot will display information about the percentage of cases affected. In addition, this section contains a survival curve. The survival curve is calculated using the Kaplan-Meier estimator based on all cases with survival data within the specified Exploration Page search. For more information on how these values are determined, please go to the Survival Analysis section. Users may choose to download the underlying data in JSON or TSV format or an image of the graph in SVG or PNG format by clicking the download icon at the top of each graph.
Below these graphs is a tabular view of the genes affected, which includes the following information:
- Symbol: The gene symbol, which links to the Gene Summary Page.
- Name: Full name of the gene.
- # SSM Affected Cases in Cohort: The number of cases affected by SSMs (simple somatic mutations) in the Cohort.
- # SSM Affected Cases Across the GDC: The number of cases within all the projects in the GDC that contain a mutation on this gene. Clicking the red arrow will display the cases broken down by project.
- # CNV Gain: The number of CNV (copy number variation) events detected in that gene which resulted in an increase (gain) in the gene's copy number.
- # CNV Loss: The number of CNV events detected in that gene which resulted in a decrease (loss) in the gene's copy number.
- # Mutations: The number of SSMs (simple somatic mutations) detected in that gene.
- Annotations: Includes a COSMIC symbol if the gene belongs to The Cancer Gene Census.
- Survival: An icon that, when clicked, will plot the survival rate between cases in the project with mutated and non-mutated forms of the gene.
CNV Data
The CNV visualization in GDC Exploration reports only gains, losses, or neither, however, in some situations it is important to distinguish between high level amplifications and gains, and single and double copy losses. For this, you will need to download the primary data and determine cutoffs that are suitable for your work.
Gene Summary Page
Gene Summary Pages describe each gene with mutation data and provides results related to the analyses that are performed on these genes.
The summary section of the Gene Page contains the following information:
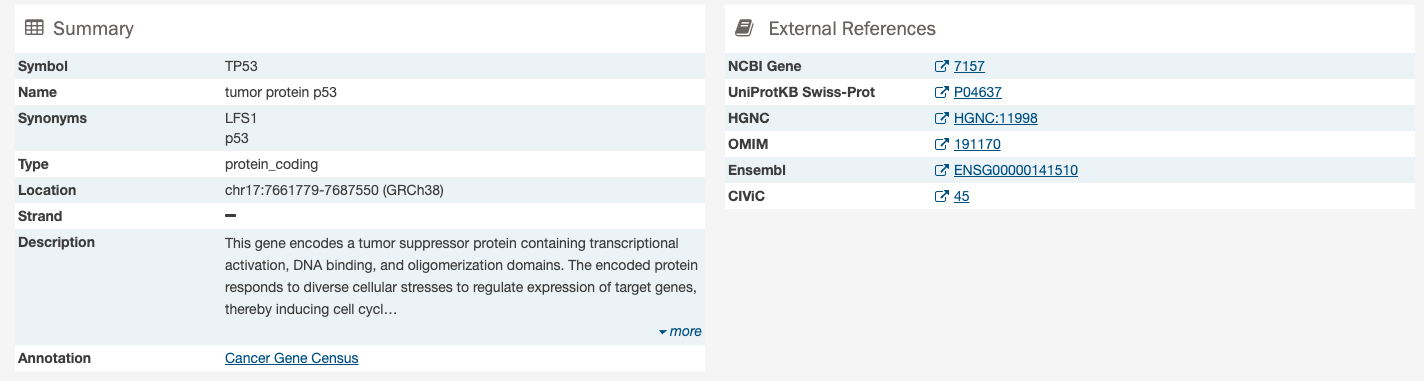
- Symbol: The gene symbol.
- Name: Full name of the gene.
- Synonyms: Synonyms of the gene name or symbol, if available.
- Type: A broad classification of the gene.
- Location: The chromosome on which the gene is located and its coordinates.
- Strand: If the gene is located on the forward (+) or reverse (-) strand.
- Description: A description of gene function and downstream consequences of gene alteration.
- Annotation: A notation/link that states whether the gene is part of The Cancer Gene Census.
External References
A list with links that lead to external databases with additional information about each gene is displayed here. These external databases include:
Cancer Distribution
A table and two bar graphs show how many cases are affected by mutations and copy number variation within the gene as a ratio and percentage. Each row/bar represents the number of cases for each project. The final column in the table lists the number of unique mutations observed on the gene for each project.
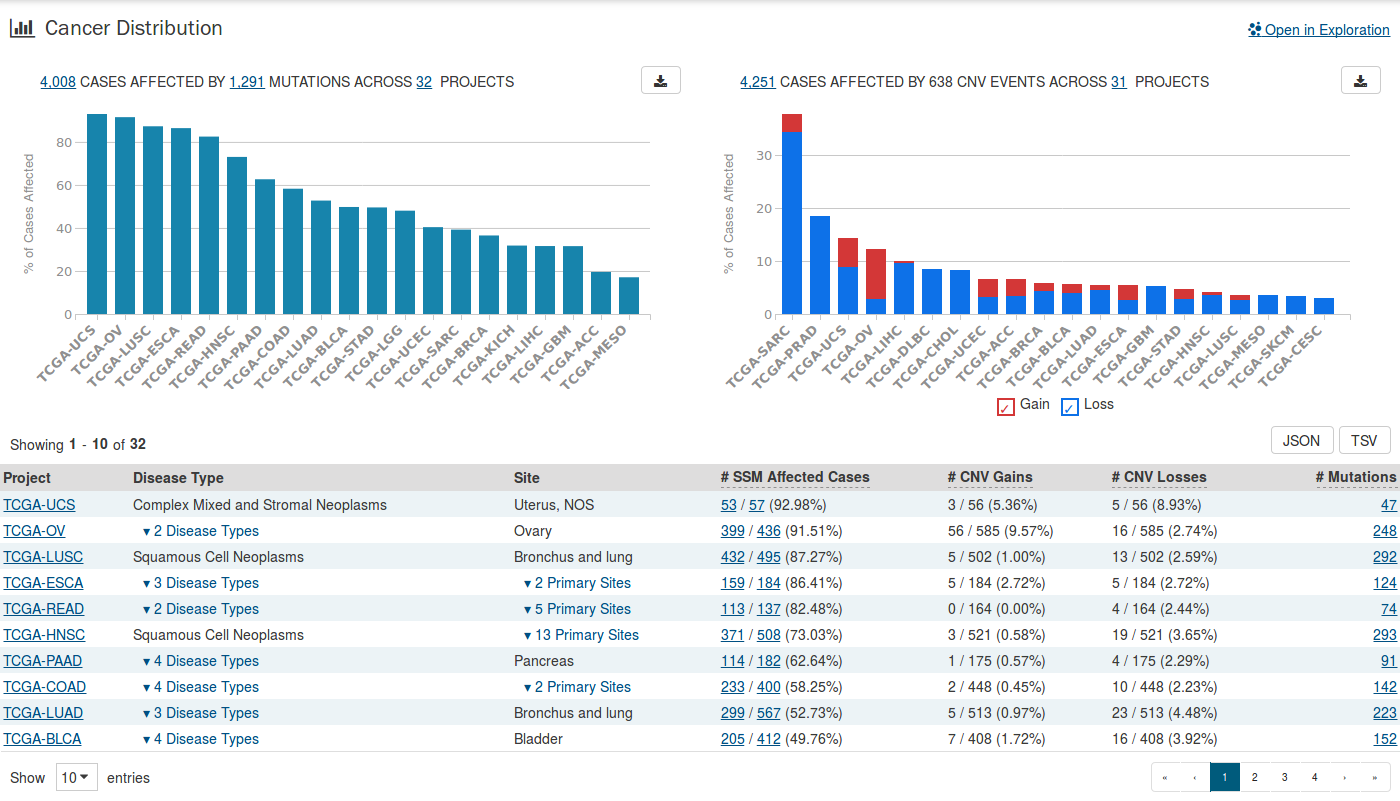
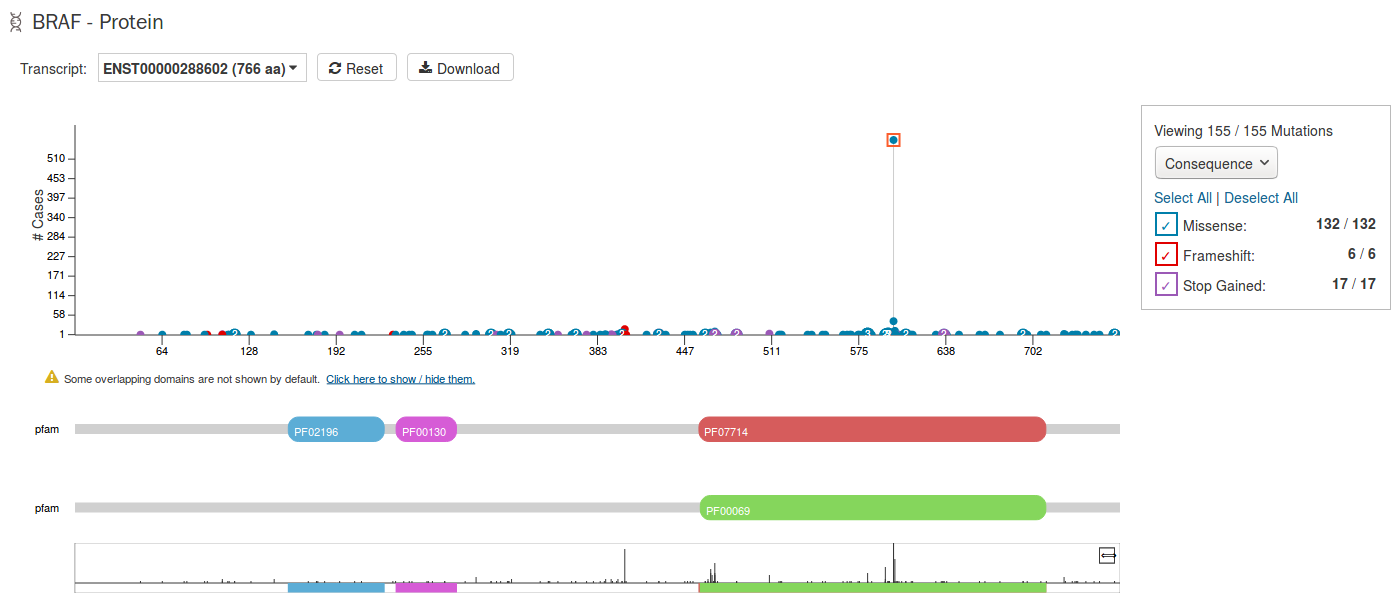
Protein Viewer
Mutations and their frequency across cases are mapped to a graphical visualization of protein-coding regions with a lollipop plot. Pfam domains are highlighted along the x-axis to assign functionality to specific protein-coding regions. The bottom track represents a view of the full gene length. Different transcripts can be selected by using the drop-down menu above the plot.
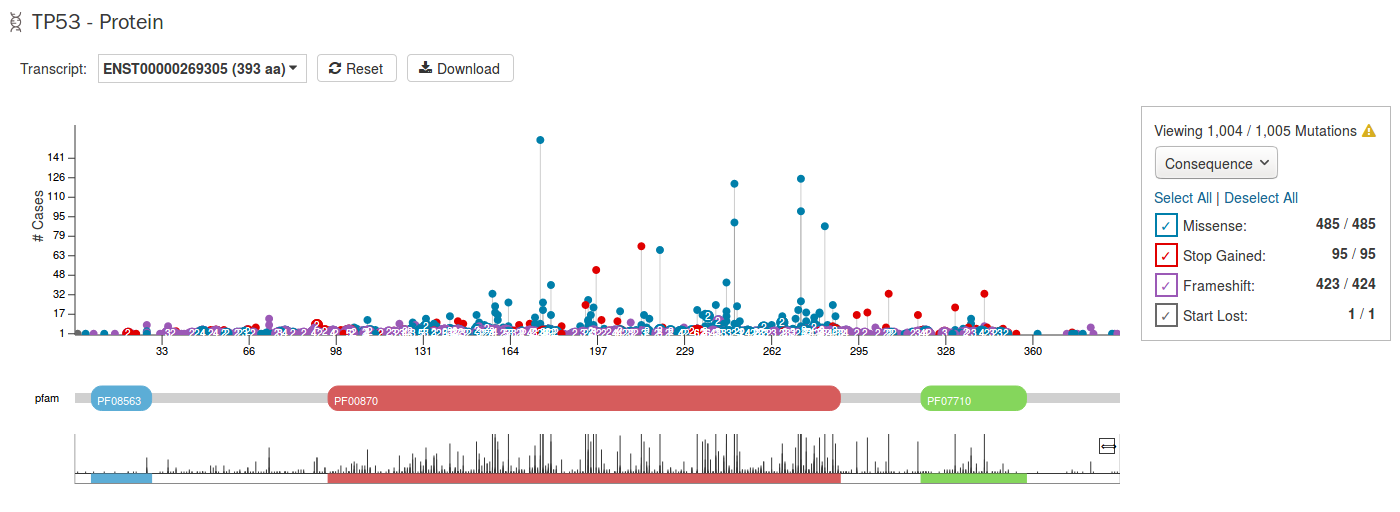
The panel to the right of the plot allows the plot to be filtered by mutation consequences or impact. The plot will dynamically change as filters are applied. Mutation consequence and impact is denoted in the plot by color.
Note: The impact filter on this panel will not display the annotations for alternate transcripts.
The plot can be viewed at different zoom levels by clicking and dragging across the x-axis, clicking and dragging across the bottom track, or double clicking the pfam domain IDs. The Reset button can be used to bring the zoom level back to its original position. The plot can also be exported as a PNG image, SVG image or as JSON formatted text by choosing the Download button above the plot.
Most Frequent Somatic Mutations
The 20 most frequent mutations in the gene are displayed as a bar graph that indicates the number of cases that share each mutation.
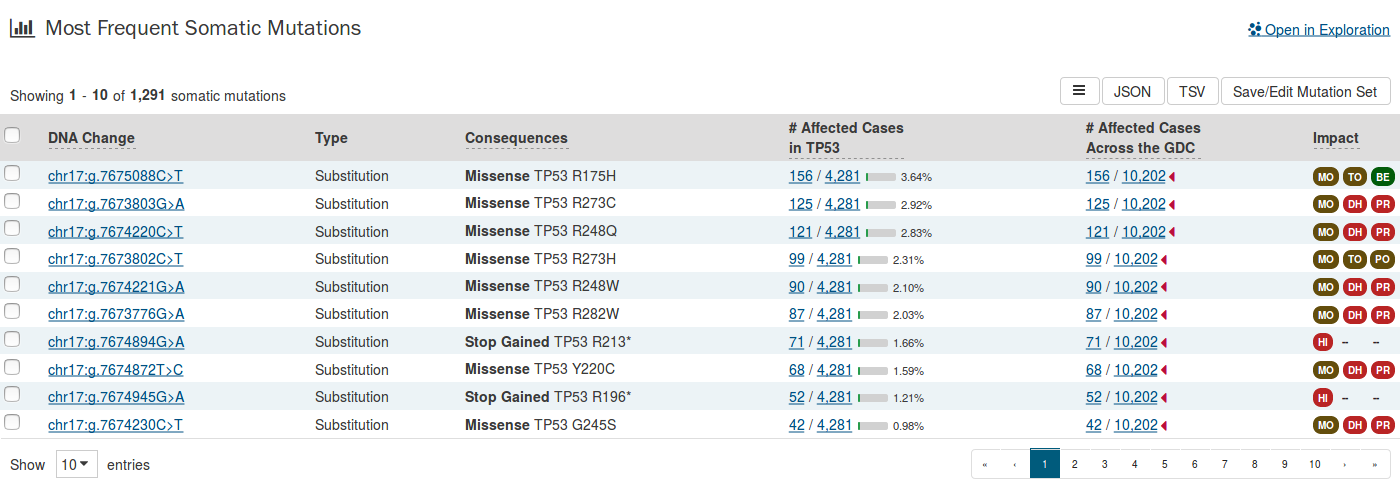
A table is displayed below that lists information about each mutation including:
- DNA Change: The chromosome and starting coordinates of the mutation are displayed along with the nucleotide differences between the reference and tumor allele.
- Type: A general classification of the mutation.
- Consequences: The effects the mutation has on the gene coding for a protein (i.e. synonymous, missense, non-coding transcript).
- # Affected Cases in Gene: The number of affected cases, expressed as number across all mutations within the selected Gene.
- # Affected Cases Across GDC: The number of affected cases, expressed as number across all projects. Choosing the arrow next to the percentage will expand the selection with a breakdown of each affected project.
- Impact: A subjective classification of the severity of the variant consequence. This is determined by three different tools:
Clicking the Open in Exploration button will navigate the user to the Exploration Page, showing the same results in the table (mutations filtered by the gene).
Mutations
The Mutations tab will give an overview of all the mutations that match the criteria of the filters (Cohort).
Open-access mutation data is displayed by defualt. To access controlled access mutations, users must apply to the correct data access authority, be granted access, and login to the portal. If a user is logged in and has been granted access to controlled-access mutations, they will be integrated with open-access mutations throughout the portal visualizations and counts.
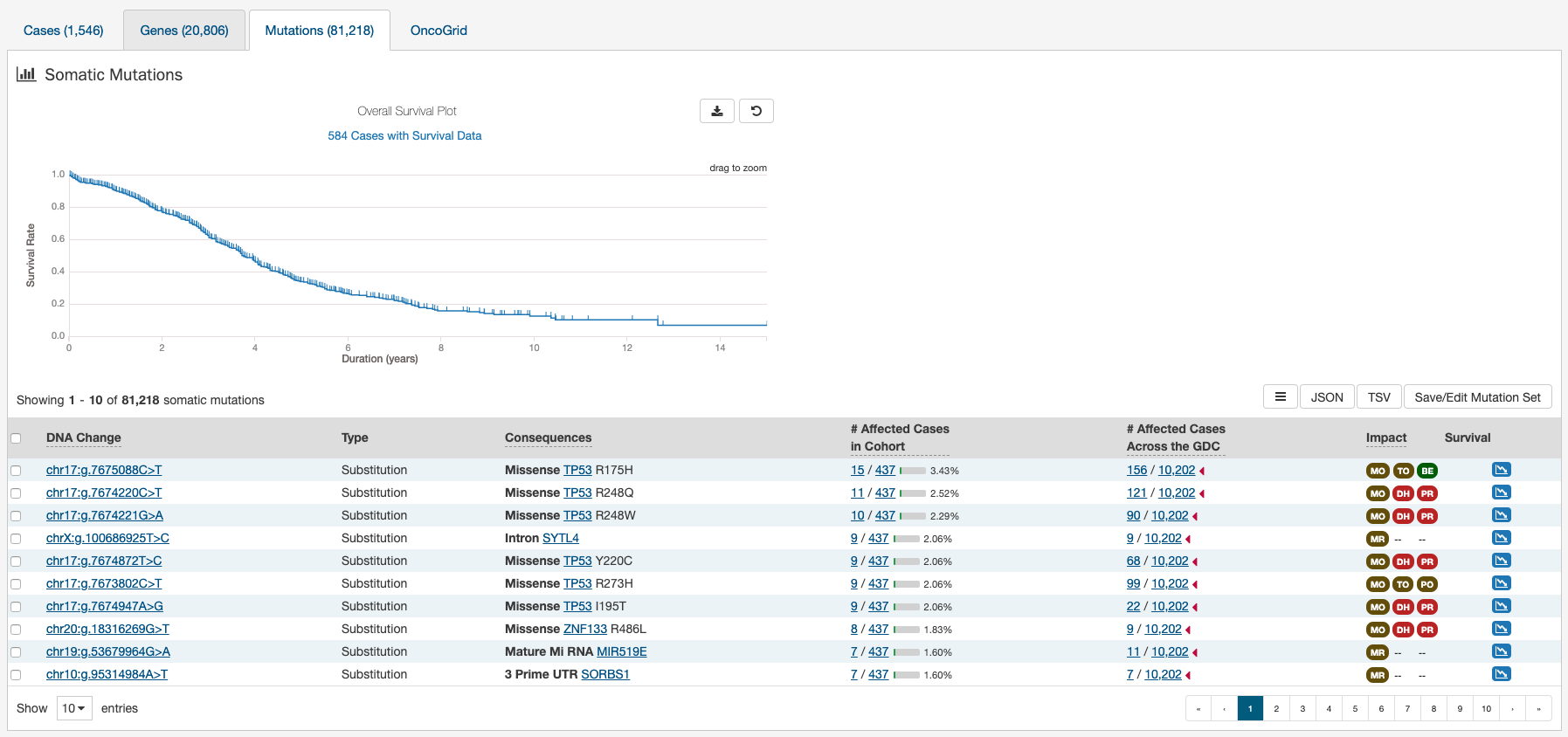
At the top of this tab contains a survival curve. The survival curve is calculated using the Kaplan-Meier estimator based on all cases with survival data within the specified Exploration Page search. For more information on how these values are determined, please go to the Survival Analysis section. Users may choose to download the underlying data in JSON or TSV format or an image of the graph in SVG or PNG format by clicking the download icon at the top of the graph.
A table is displayed below that lists information about each mutation:
- DNA Change: The chromosome and starting coordinates of the mutation are displayed along with the nucleotide differences between the reference and tumor allele.
- Type: A general classification of the mutation.
- Consequences: The effects the mutation has on the gene coding for a protein (i.e. synonymous, missense, non-coding transcript). A link to the Gene Summary Page for the gene affected by the mutation is included.
- # Affected Cases in Cohort: The number of affected cases in the Cohort as a fraction and as a percentage.
- # Affected Cases in Across all Projects: The number of affected cases, expressed as number across all projects. Clicking the arrow next to the percentage will display a breakdown of each affected project.
- Impact: A subjective classification of the severity of the variant consequence. This is determined by three different tools:
- Survival: An icon that when clicked, will plot the survival rate between the gene's mutated and non-mutated cases.
Mutation Summary Page
The Mutation Summary Page contains information about one somatic mutation and how it affects the associated gene. Each mutation is identified by its chromosomal position and nucleotide-level change.
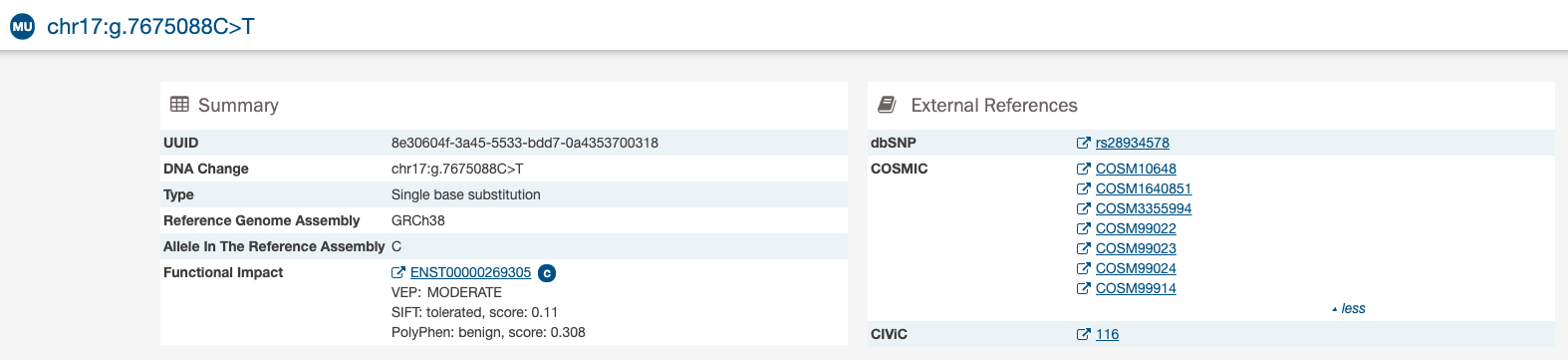
- UUID: A unique identifier (UUID) for this mutation.
- DNA Change: Denotes the chromosome number, position, and nucleotide change of the mutation.
- Type: A broad categorization of the mutation.
- Reference Genome Assembly: The reference genome in which the chromosomal position refers to.
- Allele in the Reference Assembly: The nucleotide(s) that compose the site in the reference assembly.
- Functional Impact: A subjective classification of the severity of the variant consequence.
External References
A separate panel contains links to databases that contain information about the specific mutation. These include dbSNP, COSMIC, and CIViC.
Consequences
The consequences of the mutation are displayed in a table. The set of consequence terms, defined by the Sequence Ontology.

The fields that describe each consequence are listed below:
- Gene: The symbol for the affected gene.
- AA Change: Details on the amino acid change, including compounds and position, if applicable.
- Consequence: The biological consequence of each mutation.
- Coding DNA Change: The specific nucleotide change and position of the mutation within the gene.
- Impact: A subjective classification of the severity of the variant consequence. This is determined by three different tools:
- Strand: If the gene is located on the forward (+) or reverse (-) strand.
- Transcript(s): The transcript(s) affected by the mutation. Each contains a link to the Ensembl entry for the transcript.
Cancer Distribution
A table and bar graph shows how many cases are affected by the particular mutation. Each row/bar represents the number of cases for each project.
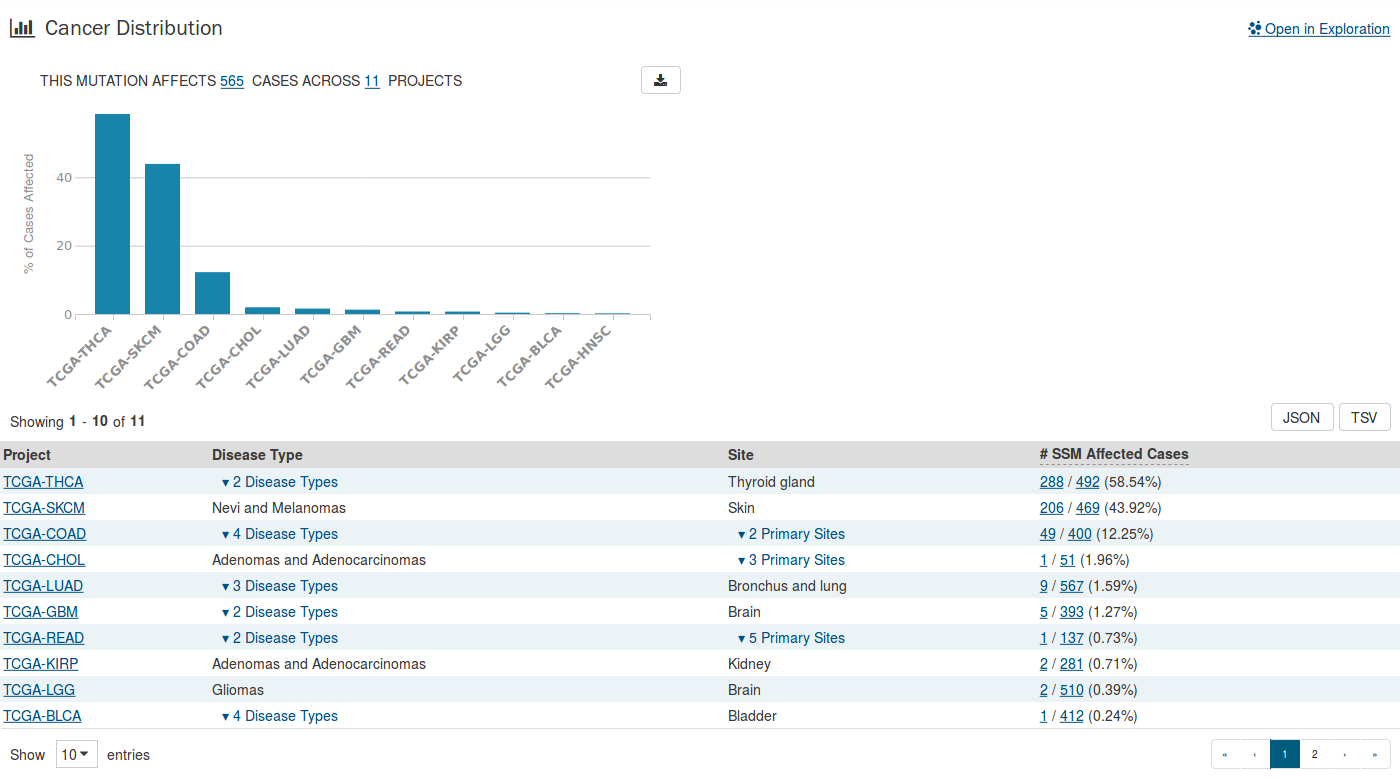
The table contains the following fields:
- Project ID: The ID for a specific project.
- Disease Type: The disease associated with the project.
- Site: The anatomical site affected by the disease.
- # SSM Affected Cases: The number of affected cases and total number of cases displayed as a fraction and percentage.
Protein Viewer
The protein viewer displays a plot representing the position of mutations along the polypeptide chain. The y-axis represents the number of cases that exhibit each mutation, whereas the x-axis represents the polypeptide chain sequence. Pfam domains that were identified along the polypeptide chain are identified with colored rectangles labeled with pfam IDs. See the Gene Summary Page for additional details about the protein viewer.
OncoGrid
The Exploration Page includes an OncoGrid plot of the cases with the most mutations, for the top 50 mutated genes affected by high impact mutations. Genes displayed on the left of the grid (Y-axis) correspond to individual cases on the bottom of the grid (X-axis). Additionally, the plot also indicates in each cell any CNV events detected for these top mutated cases and genes.
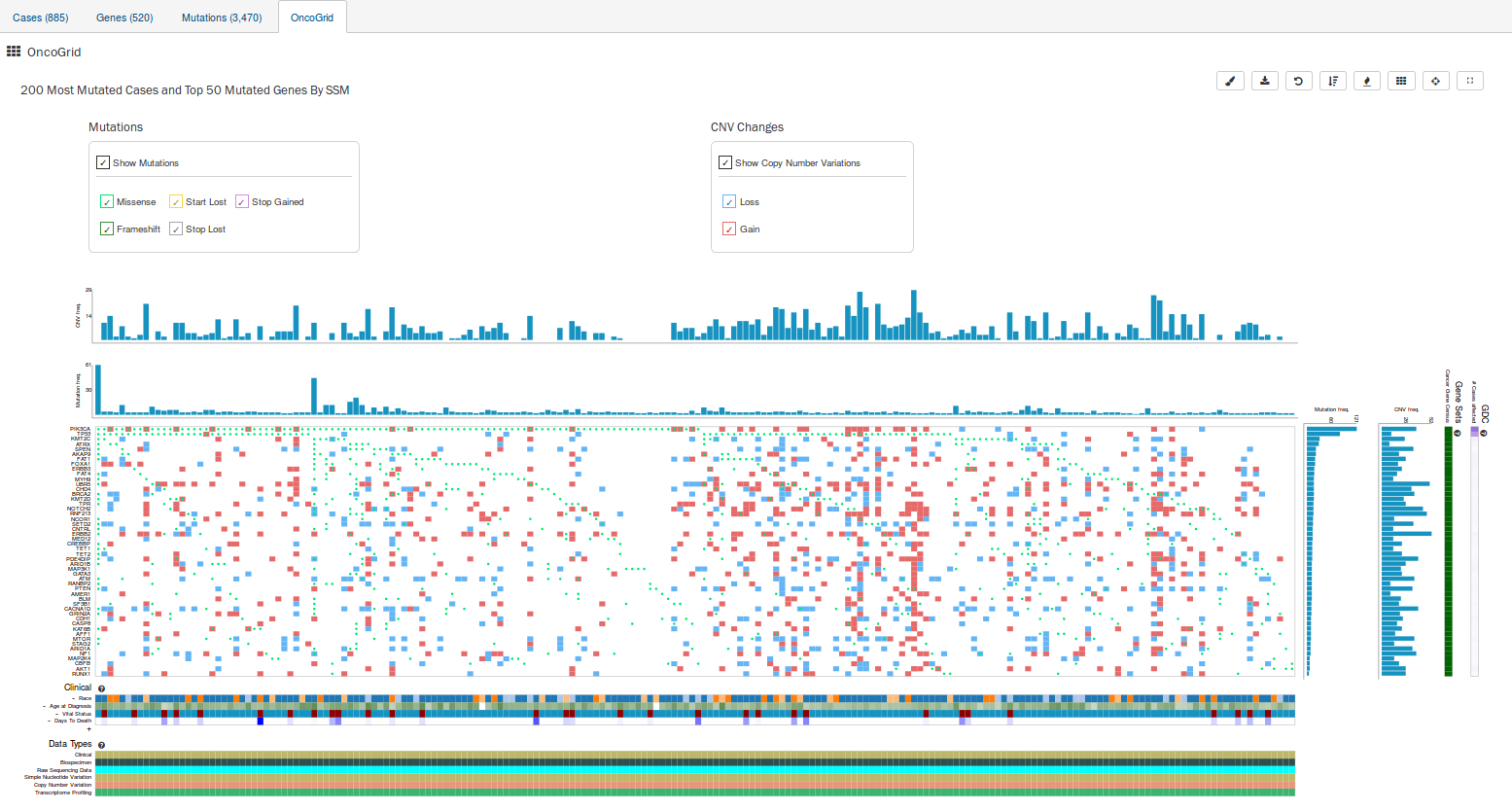
The grid is color-coded with a legend at the top which describes what type of mutation consequence and CNV event is observed for each gene/case combination. Clinical information and the available data for each case are available at the bottom of the grid.
The right side of the grid displays additional information about the genes:
- Gene Sets: Describes whether a gene is part of The Cancer Gene Census. (The Cancer Gene Census is an ongoing effort to catalogue those genes for which mutations have been causally implicated in cancer)
- # Cases Affected: Identifies all cases in the GDC affected with a mutation in this gene
OncoGrid Options
To facilitate readability and comparisons, drag-and-drop can be used to reorder the gene rows. Double clicking a row in the "# Cases Affected" bar at the right side of the graphic launches the respective Gene Summary Page. Hovering over a cell will display information about the mutation such as its ID, affected case, and biological consequence. Clicking on the cell will bring the user to the respective Mutation Summary Page.
A tool bar at the top right of the graphic allows the user to export the data as a JSON object, PNG image, or SVG image. Seven buttons are available in this toolbar:
- Customize Colors: Users can customize the colors that represent mutation consequence types and CNV gains/losses.
- Download: Users can choose to export the contents either to a static image file (PNG or SVG format) or the underlying data in JSON format.
- Reload Grid: Sets all OncoGrid rows, columns, and zoom levels back to their initial positions.
- Cluster Data: Clusters the rows and columns to place mutated genes with the same cases and cases with the same mutated genes together.
- Toggle Heatmap: The view can be toggled between cells representing mutation consequences or number of mutations in each gene.
- Toggle Gridlines: Turn the gridlines on and off.
- Toggle Crosshairs: Turns crosshairs on, so that users can zoom into specific sections of the OncoGrid.
- Fullscreen: Turns Fullscreen mode on/off.
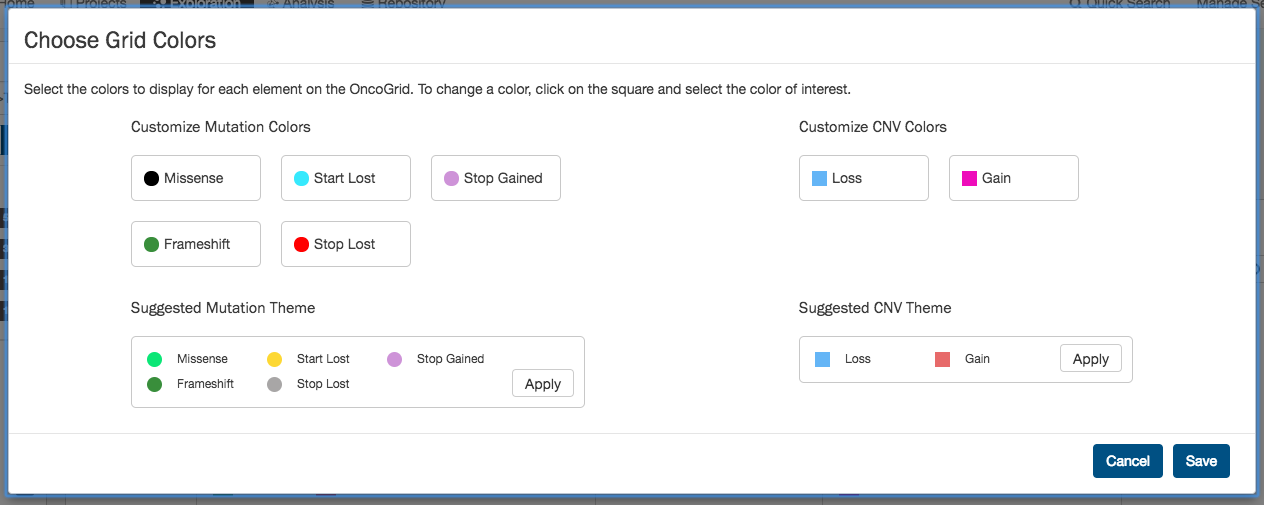
OncoGrid Color Picker
To customize the colors for mutation consequence types and CNV gains/losses, a user can click the color picker icon in the OncoGrid toolbar.
- Customize Colors: Opens a control where the user can pick their own colors or apply a suggested theme and save their changes.
- Reset to Default: Resets all colors to the defaults initially used by OncoGrid.
File Navigation
After utilizing the Exploration Page to narrow down a specific cohort, users can find the specific files that relate to this group by clicking on the View Files in Repository button as shown in the image below.
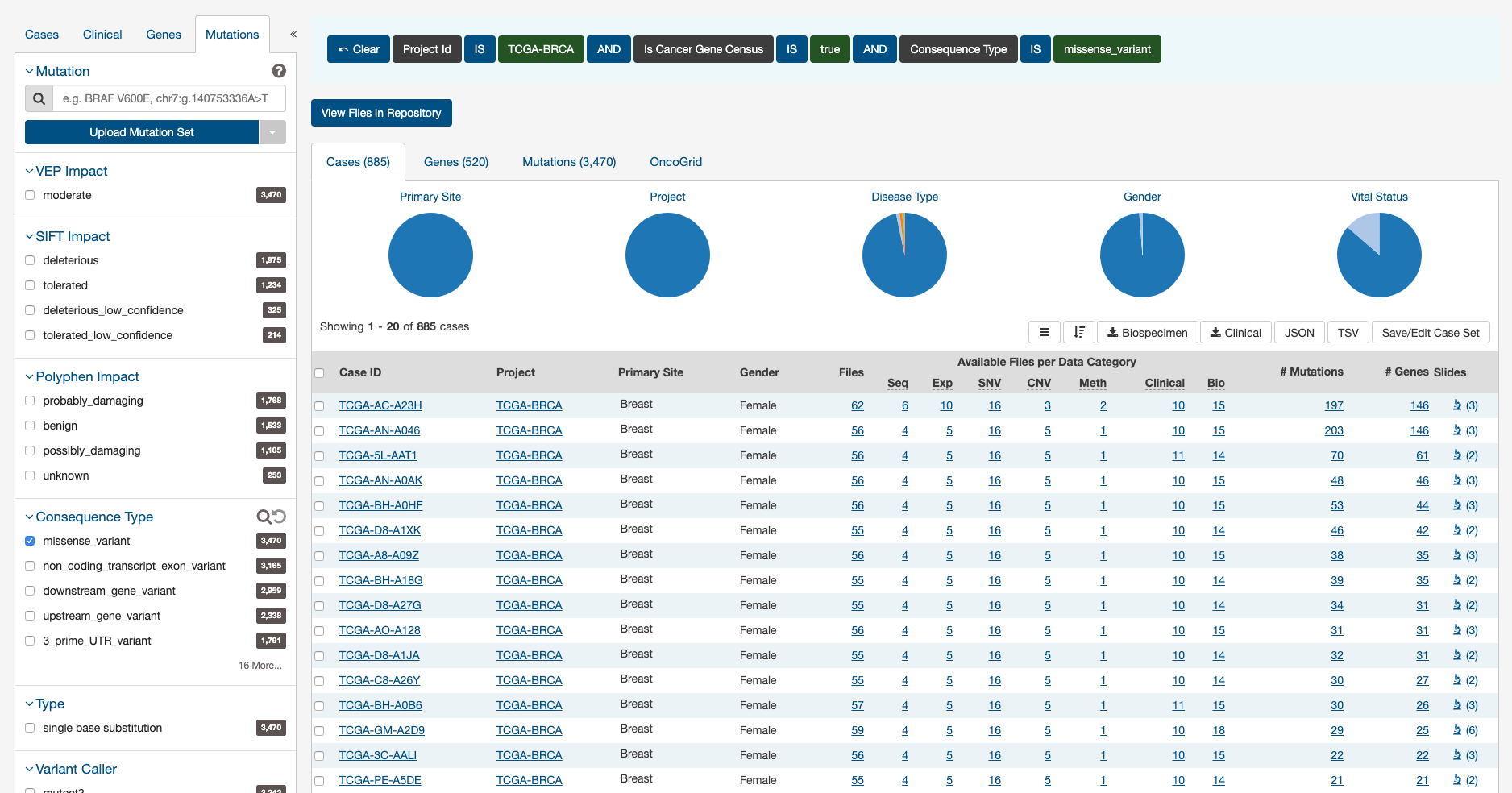
Clicking this button will navigate the users to the Repository Page, filtered by the cases within the cohort.
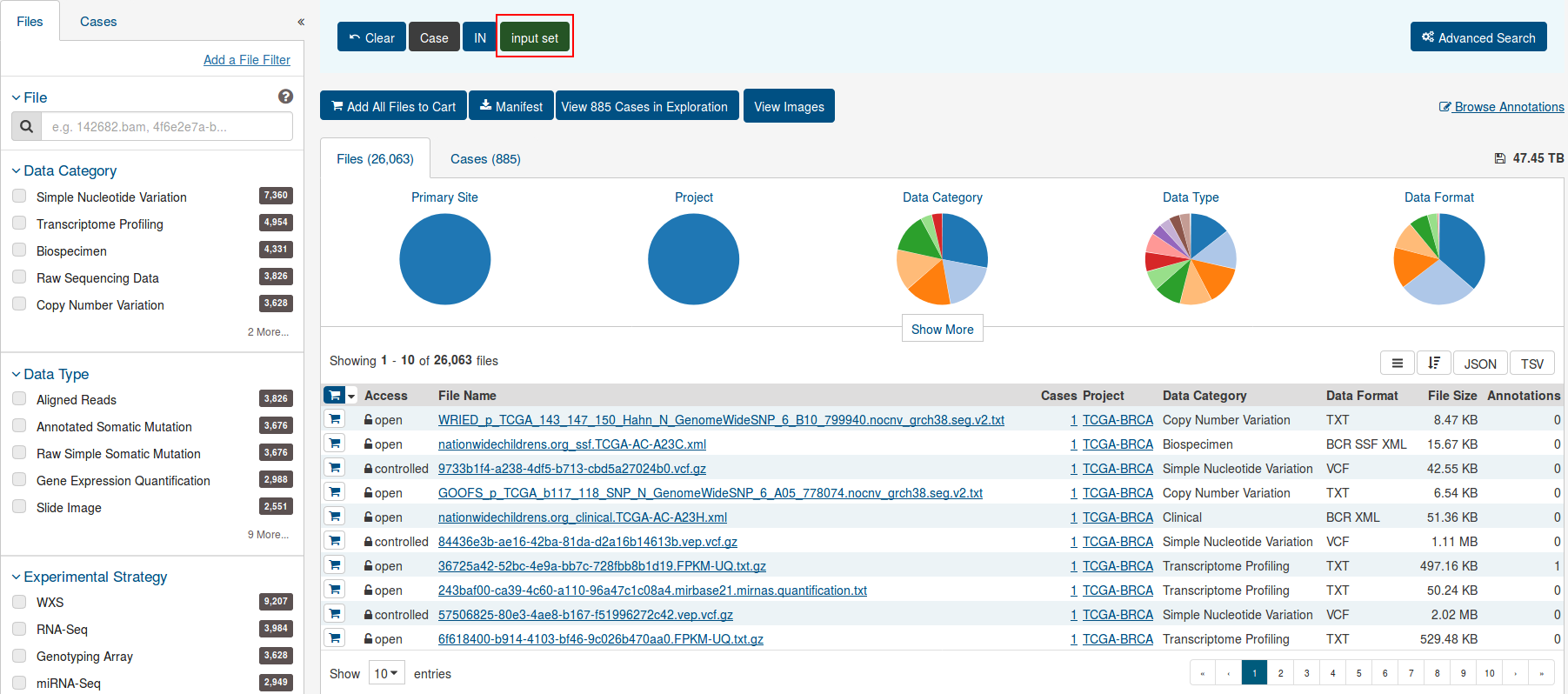
The filters chosen on the Exploration Page are displayed as an input set on the Repository Page. Additional filters may be added on top of this input set, but the original set cannot be modified and instead a new input set must be created from original data.
Survival Analysis
The survival analysis, which is seen in both the Gene and Mutation tabs, is used to analyze the occurrence of event data over time. In the GDC, survival analysis is performed on the mortality of the cases. Thus, the values are retrieved from GDC Data Dictionary properties and a survival analysis requires the following fields:
- Data on the time to a particular event (days to death or last follow up).
- Fields: demographic.days_to_death or demographic.days_to_last_follow_up
- Information on whether the event has occurred (alive/deceased).
- Fields: demographic.vital_status
- Data split into different categories or groups (i.e. gender, etc.).
- Fields: demographic.gender
The survival analysis in the GDC uses a Kaplan-Meier estimator:

Where:
- S(t) is the estimated survival probability for any particular one of the t time periods.
- ni is the number of subjects at risk at the beginning of time period ti.
- and di is the number of subjects who die during time period ti.
The table below is an example data set to calculate survival for a set of seven cases:

The calculated cumulated survival probability can be plotted against the interval to obtain a survival plot like the one shown below.
